
Redis에 대해 알아보자 ❕
1. Redis (Remote Dictionary Server)
Redis는 NoSQL 중 하나로, 인메모리 데이터 저장소이다. key-value 데이터 구조에 기반한 다양한 형태의 자료구조를 제공하며, pub/sub같은 다양한 기능도 제공하여 다양한 목적으로 사용된다.

Redis에서 Remote는 Redis가 각각의 서버 안에 로컬하게 존재하지 않고, 다수의 서버에서 공통적으로 사용할 수 있도록 원격에 존재한다는 의미이며, Dictionary는 해시맵과 같이 key-value 형태로 상수의 시간 복잡도로 사용이 가능하다는 의미이다.
→ 즉, 다수의 서버를 사용하는 분산 환경의 서버가 공통으로 사용할 수 있는 해시 테이블로 생각하면 된다.
1-1. Redis 특징
- 인메모리 저장소
- 모든 데이터를 메모리에 저장한다. (백업 / 스냅샷 제외)
- 메모리에서 관리하므로 매우 빠른 속도로 데이터를 저장 및 조회할 수 있다.
- 영구적으로 디스크에 저장할 수 있는 백업 기능을 제공한다.
- 캐싱
- 휘발성
- 단일 스레드
- 단일 스레드에서 모든 태스크를 처리한다.
- 실행한 명령어들을 이벤트 루프방식으로 처리한다.
- 클러스터 모드
- 다중 노드에 데이터를 분산 저장하여 안정성 & 고가용성을 제공한다.
- 영속성
- 디스크에 영구적으로 저장할 수 있는 기능을 제공한다.
- *RDB 방식 + *AOF 방식으로 영속성 옵션 제공
- Pub/Sub
- Pub/Sub 패턴을 지원하여 채팅과 알림 등의 애플리케이션 개발이 편리하다.
이 외에도 다양한 데이터 타입을 지원하고, 클라이언트 라이브러리가 많아서 연동하기 쉽다는 특징이 있다. 이러한 특징 덕분에 Redis는 캐싱, 비율 계산기, 메시지 큐, 실시간 분석, 채팅 등에서 자주 사용된다.
* RDB, AOF ?
레디스는 주로 캐시로 사용되기 때문에 기본적으로 손실되어도 무방한 데이터를 기록해야 하는데, 하지만 실제 서비스를 운영하다보면 캐시라 할지라도 데이터가 손실되었을 때, 서비스 지연이 발생하거나 장애 상황으로 이어질 수 있기때문에 다음과 같은 옵션을 제공한다.
- RDB (Redis Database)
- 메모리에 있는 데이터 전체에서 스냅샷을 작성하고, 이를 디스크로 저장하는 방식
- 스냅샷 이후 변경된 데이터는 복구할 수 없기 때문에 사용 시 주의해야 한다.
- 재난 복구 또는 복제에 주로 사용된다.
- AOF (Append Only File)
- 데이터가 변경되는 이벤트가 발생하면 모두 로그에 저장하는 방식
- 모든 데이터 변경 기록들을 보관하므로 최신 데이터 정보를 백업 가능하다.
- RDB 방식에 비해 데이터 유실량이 적다. 하지만 Write 작업을 다시 적용하기 때문에 로딩 속도가 느리다.
서비스에 적합한 방식을 택해서 사용해야 한다. Redis에서는 영속성 옵션을 사용하지 않거나 두가지 옵션을 각각 사용하거나 두가지 옵션을 모두 사용할 수 있다. 일반적으로 특정 시간마다 RDB 스냅샷을 생성하고, 그 이후에 변경되는 데이터는 AOF로 백업하는 방식으로 RDB와 AOF를 조합하여 데이터를 백업한다고 한다.
레디스 동작

Redis는 명령들이 이벤트 루프 방식으로 처리된다. 클라이언트가 실행한 명령을 event queue에 적재하고, 싱글 스레드로 하나씩 처리하는 방식이다. 메모리를 사용하기 때문에 싱글 스레드로 데이터를 빠르게 처리할 수 있다. 따라서 컨텍스트 스위칭이 발생하지 않고 데드락이 발생하지 않는다는 장점이 있다. 하지만 오버헤드가 큰 명령어를 처리한다면 다른 명령들의 응답 속도가 길어질 수 있다는 단점이 있다.
1-2. 캐시 패턴
캐싱을 진행할 때는 다양한 패턴들이 존재하며, 서비스의 요구사항과 성능에 따라 적절히 사용해야 한다. 주로 대표적으로 사용되는 패턴은 Cache-Aside, Write-Through, Write-Behind가 있다.
1. Cache-Aside 패턴
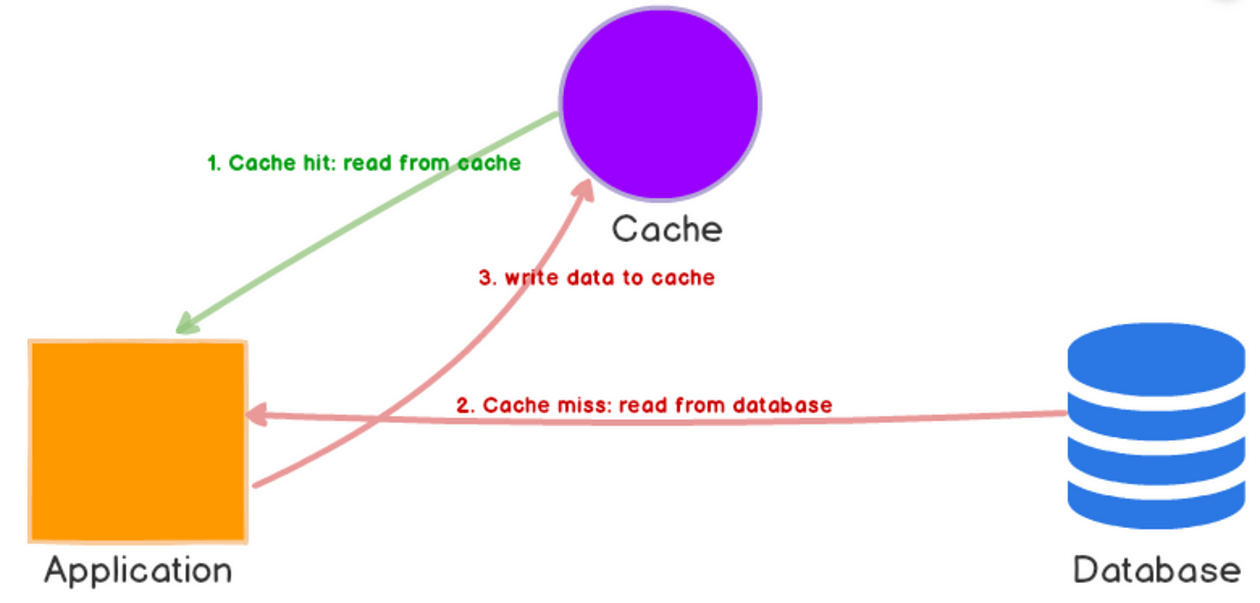
클라이언트 요청을 조회할 때, 애플리케이션에서 캐시를 조회하여 cache hit인 경우 그대로 캐시를 사용해 요청을 처리하고, cache miss인 경우 원본 스토리지에서 데이터를 조회하여 캐싱한 뒤 데이터를 반환하는 방식이다. 코드가 간단하고 조회 성능을 높일 수 있지만 일관성을 보장하기 위해 데이터 만료 시간 설정에 주의해야 한다.
2, Write-Through 패턴

클라이언트 요청을 저장할 때, 애플리케이션에서 캐시와 원본 스토리지에 동시에 기록하는 방식으로, 모든 쓰기 요청이 캐시에 반영되므로 일관성이 높아진다. 하지만 쓰기 작업이 빈번한 경우 부하가 생길 수 있다.
3. Write-Behind 패턴

데이터가 변경되면 먼저 캐시에만 저장하고 원본 데이터 저장소에는 비동기적으로 업데이트하는 방식으로, 쓰기 성능은 향상되지만 원본 스토리지로의 데이터 반영이 지연될 수 있어 일관성 문제가 생길 수 있다.
이러한 캐시 패턴은 데이터의 최신성, 일관성 및 시스템의 성능을 보장하기 위해 적절히 사용해야 한다. 또한, 제한된 메모리를 어떻게 효율적으로 사용할 건지에 대한 캐시 전략도 신경써줘야 한다.
2. Redis 데이터 타입
Redis에는 다양한 데이터 타입을 제공한다. 일반적으로 콜론을 이용해 의미별로 구분하고, 데이터가 없다는 것을 null이 아닌 nil로 표현한다.

Strings
- 문자열, 숫자, JSON string 등을 저장한다.
- Redis는 별도의 integer 타입없이 string으로 숫자를 저장한다.
- `SET`, `MSET`
- 값을 저장할 때 사용
- 단일 key-value를 저장할 때, 다중 key-value를 저장할 때 사용
- `INCR`, `INCRBY`
- 숫자 형태의 더하기 빼기 연산 시 사용
- increase, increase by의 약자로 1을 더할 때, 특정 수를 더할 때 사용

Lists
- String을 LinkedList로 저장한다. 그 중에서도 Doubly LinkedList이다.
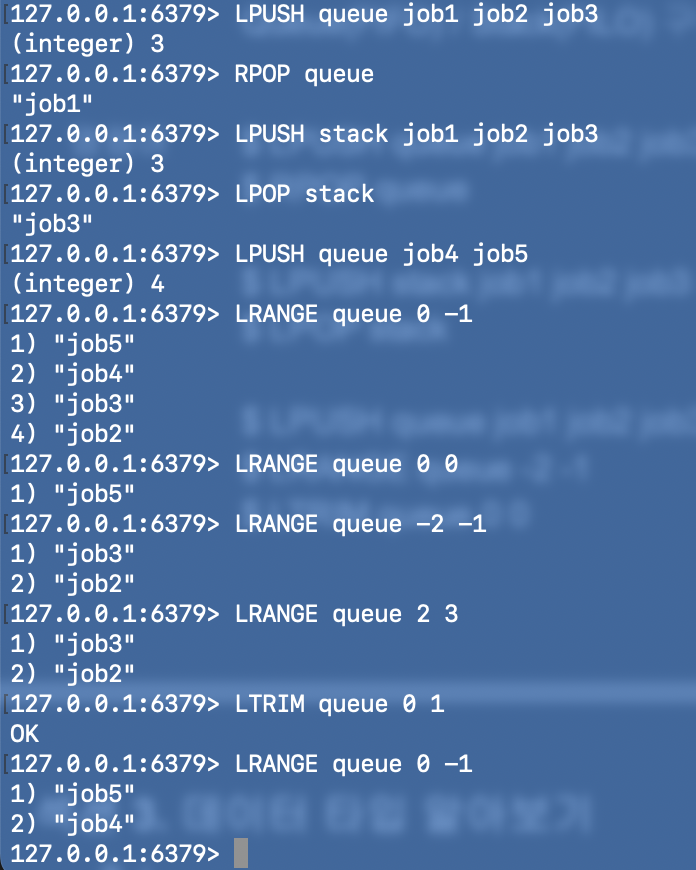
- `LPUSH`, `RPUSH`, `RPOP`, `LPOP`
- LPUSH, RPOP을 통해 Queue를 구현
- LPUSH, LPOP을 통해 Stack을 구현
- `LRANGE`
- 인덱스를 이용해 다수의 아이템 조회 가능
- 인덱스는 왼쪽부터 카운팅하면 0부터 시작하여 점차 증가, 오른쪽부터 카운팅하면 -1부터 점차 감소
- `LTRIM`
- 원하는 데이터만 남기고 싶을 때 사용
- 예를들어, `LTRIM queue 0 0`은 가장 마지막에 추가된 아이템만 남기고 나머지는 모두 삭제한다.
Sets
- 순서가 보장되지 않으며, 유니크한 값을 저장한다.
- `SADD`, `SMEMBERS`
- 데이터 추가, set의 모든 멤버를 출력
- `SADD use:1:fruits apple banana orange orange`를 넣어도 orange는 중복되어 저장되지 않는다.
- `SCARD`
- set의 카디널리티(고유한 아이템의 개수)를 출력
- `SISMEMBER`
- 특정 아이템이 set에 포함되었는지 확인
- `SINTER`, `SDIFF`, `SUNION`
- 교집합, 차집합, 합집합
- `SINTER user:1:fruits user:2:fruits`는 유저1과 유저2가 공통으로 좋아하는 과일을 출력
- `SDIFF user:1:fruits user:2:fruits`는 유저1은 좋아하지만 유저2는 안좋아하는 과일

Hashes
- key - {field: value} 구조를 갖는 데이터 타입
- `HSET`, `HGET`, `HMGET`
- 하나의 해시에 다수의 field-value를 저장
- 하나의 해시에서 field를 통해 값 조회
- 여러 field 조회
- `HINCRBY`
- 해시의 특정 field의 특정 수를 더하는 것

Sorted Sets
- 유니크한 string을 연관된 score를 통해 정렬된 집합(Set의 기능 + scroe 속성 저장)
- score에 따라 정렬을 유지한다. score가 동일하면 사전 순으로 정렬
- `ZADD`, `ZRANGE`, `ZRANK`
- `ZRANK`는 해당 아이템의 랭킹을 반환한다. (0부터 시작)
- `REV WITHSCORES` 키워드를 추가하면 역순 + 스코어와 함께 출력

Streams
- 이벤트성 로그를 저장할 때 사용하는 타입
- `XADD`, `XRANGE`
- 스트림에 엔트리를 추가, 다수의 메세지를 조회
- 엔트리를 추가할 때 key뒤에 ‘*’ 옵션을 주면 자동으로 유니크한 아이디가 할당된다.

Bitmaps
- 인터페이스 중 하나로, String을 활용해 비트 연산을 사용할 수 있도록 함
- 최대 42억개 binary 데이터를 표현할 수 있다. (2^32)
- 매우 적은 메모리를 사용해 데이터를 저장할 수 있다.
- `GETBIT`
- 해당 비트의 값 조회
- `BITOP`
- 비트 연산자 계산 (`AND` : 뒤에서 모든 결과에 1인 애들만 출력)
- 비트맵 결과를 새로운 비트맵으로 생성하기 때문에 이를 지정해줘야 한다. (`result`)
- 출석체크 같은 기능에 사용할 수 있다.

HyperLogLog
- 집합의 카디널리티를 추정할 때 사용
- 멤버의 값을 해싱하여 버킷 단위로 분류해서 저장한다. 따라서 카디널리티를 일정하게 계산할 수 있다.
- 실제 값을 저장하지 않기 때문에, 적은 메모리로 카디널리티를 계산할 수 있다.
- 모든 아이템을 출력해야 하는 경우 활용할 수 없다.

BloomFilter
- 요소가 집합 안에 포함되었는지 확인할 수 있는 확률형 자료 구조
- HyperLogLog와 마찬가지로, 정확성을 일부 포기하고 저장공간을 효율적으로 사용할 수 있다.
- 실제 값을 저장하지 않기 때문에 적은 메모리를 사용한다.
- 저장원리
- 값을 해싱하여 여러 개의 해시 키를 만들어내고, 키에 해당하는 위치를 블룸필터에 표시한다. 이후에 어떤 아이템이 존재하는지 확인할 때, 키에 대한 블룸필터 위치를 확인한다.
- False Positive
- 데이터가 집합에 포함되지 않은데 포함되었다고 잘못 예측하는 경우가 있다. 사용전에 이를 반드시 인지하고 있어야 한다. (but, 있는데 없다고 하는 경우는 없다)
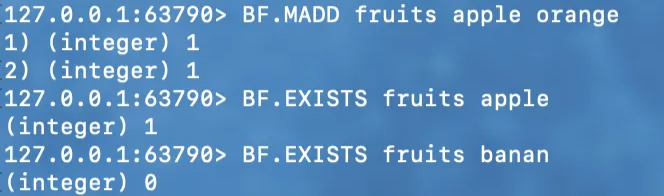
- `BF.MADD`, `BF.EXISTS`
- 데이터 추가, 존재 여부 확인
블룸 필터를 사용하려면 모듈을 설치해야 한다. 따라서 실제 redis에 설치하지 않고, docker로 `redis/redis-stack-server`를 포트 `63790`번으로 실행시키고, 터미널에 `redis-cli -p 63790`을 실행해 블룸 필터를 사용했다.
특수 명령어
- `EXPIRE` : 데이터를 특정시간 이후에 만료 시키는 기능. 만료되자마자 삭제하지 않고, 나중에 백그라운드 태스크에 의해 주기적으로 삭제된다.
- `TTL` : 남은 만료시간 확인
- `SETEX` : 데이터를 저장하는 동시에 만료 시간 설정
- `SET NX`, `SET XX` : NN은 해당 key가 존재하지 않은 경우에만 set, XX는 해당 key가 존재하는 경우에만 set
- `PUBLISH`, `SUBSCRIBE` : pub/sub 동작

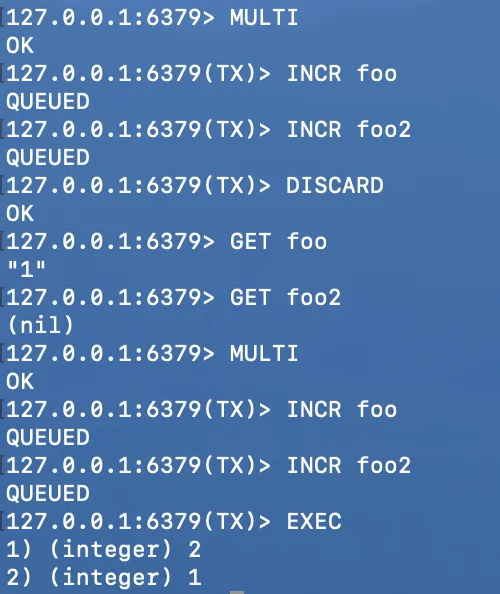
- `MULTI`, `DISCARD`, `EXEC` : 트랜잭션 기능. 각 트랜잭션 시작, 롤백, 커밋
이 외에도 다양한 타입이 존재한다.
Understand Redis data types
Overview of data types supported by Redis
redis.io
3. 활용 및 예시
- 분산락 : `SET NX` 사용. 공유 자원을 표현할 수 있는 이름을 통해 락의 키를 설정하고, NX 옵션을 통해 해당 키가 존재하지 않은 경우에만 락을 획득하여 작업을 실행
- 유저 접속 상태 : `Bitmap` 사용. 현재 시간의 분을 기준으로 key 생성해서 해다 유저가 서버와 통신을 주고받고 있는 경우에 비트값을 1로 업데이트하고, 이후 통신하고 있지 않으면 비트값이 업데이트 하지 않고 유저의 상태를 오프라인으로 표시
- 방문자 확인 : `HyperLogLog` 사용. 방문자 수를 대략적으로 추정하는 경우. 예를 들어, 유저의 id로 카운팅하고 PFCOUNT를 통해 카디널리티 조회
- 중복 요청 방지 : `BloomFilter` 사용. 이벤트 데이터를 기준으로 해싱하고, 이벤트 발생 시간에 따라 고유한 id를 통해 저장. 이후에 중복 요청이 실행된다면 id를 기준으로 블룸필터 조회하고, 이미 존재한다면 false positive일 수도 있기 때문에 원본 스토리지를 한 번 더 조회하고 데이터를 처리
- 채팅 및 메시징 : `Pub/Sub` 사용.
- 대기열 : `List` 사용
4. 주의점
대부분의 레디스 명령어는 O(1)의 시간복잡도를 갖지만, 일부 명령어의 경우 O(N)이니 주의해야 한다. 특히 레디스는 단일 스레드에서 모든 요청을 순차적으로 처리하기 때문에, 특정 명령으로 인해 전체 애플리케이션의 성능을 저하시킬 수도 있다.
O(N) 명령어
- `KEYS *`
- `SMEMBERS`
- `HGETALL`
- `SORT`
5. 마무리
최근 프로젝트에 Redis를 적용하면서 캐싱 기술을 적용하는 것이 서비스를 개발하는데 큰 도움이 된다는 것을 알게 되었다. 이번 학습을 통해 레디스에 장점과 활용 사례를 알게되었고, 캐싱을 적용하는 것도 중요하지만 캐시를 어떻게 관리하는지도 주의해야 한다는 것을 깨닫게 되었다. 아직 실무에서는 사용해보지 못했지만, 이런 데이터 타입이 존재하고 캐싱을 왜 사용하는지에 대해 이해하게 되어서, 추후 개발에서는 이러한 기술에 대해 신중히 고민하고 도입하며 개발해야 겠다.
참고자료 😃
https://velog.io/@banggeunho/레디스Redis-알고-쓰자.-정의-저장방식-아키텍처-자료구조-유효-기간
https://www.inflearn.com/course/실전-redis-활용
https://aws.amazon.com/ko/elasticache/what-is-redis/
https://redis.io/docs/latest/develop/data-types/
https://medium.com/@mmoshikoo/cache-strategies-996e91c80303
'DB' 카테고리의 다른 글
| [DB] JDBC, DBCP (+Connection, Connection Pool) (0) | 2024.05.24 |
|---|---|
| [DB] B-Tree, B+Tree - DB Index (0) | 2024.04.18 |
| [DB] NoSQL (NotOnly SQL) (1) | 2024.03.28 |
| [DB] 데이터베이스 정규화 (Normalization) (1) | 2024.03.26 |
| [DB] 트랜잭션 격리수준 (Transaction Isolation) (0) | 2024.03.15 |
Redis에 대해 알아보자 ❕
1. Redis (Remote Dictionary Server)
Redis는 NoSQL 중 하나로, 인메모리 데이터 저장소이다. key-value 데이터 구조에 기반한 다양한 형태의 자료구조를 제공하며, pub/sub같은 다양한 기능도 제공하여 다양한 목적으로 사용된다.
Redis에서 Remote는 Redis가 각각의 서버 안에 로컬하게 존재하지 않고, 다수의 서버에서 공통적으로 사용할 수 있도록 원격에 존재한다는 의미이며, Dictionary는 해시맵과 같이 key-value 형태로 상수의 시간 복잡도로 사용이 가능하다는 의미이다.
→ 즉, 다수의 서버를 사용하는 분산 환경의 서버가 공통으로 사용할 수 있는 해시 테이블로 생각하면 된다.
1-1. Redis 특징
- 인메모리 저장소
- 모든 데이터를 메모리에 저장한다. (백업 / 스냅샷 제외)
- 메모리에서 관리하므로 매우 빠른 속도로 데이터를 저장 및 조회할 수 있다.
- 영구적으로 디스크에 저장할 수 있는 백업 기능을 제공한다.
- 캐싱
- 휘발성
- 단일 스레드
- 단일 스레드에서 모든 태스크를 처리한다.
- 실행한 명령어들을 이벤트 루프방식으로 처리한다.
- 클러스터 모드
- 다중 노드에 데이터를 분산 저장하여 안정성 & 고가용성을 제공한다.
- 영속성
- 디스크에 영구적으로 저장할 수 있는 기능을 제공한다.
- *RDB 방식 + *AOF 방식으로 영속성 옵션 제공
- Pub/Sub
- Pub/Sub 패턴을 지원하여 채팅과 알림 등의 애플리케이션 개발이 편리하다.
이 외에도 다양한 데이터 타입을 지원하고, 클라이언트 라이브러리가 많아서 연동하기 쉽다는 특징이 있다. 이러한 특징 덕분에 Redis는 캐싱, 비율 계산기, 메시지 큐, 실시간 분석, 채팅 등에서 자주 사용된다.
* RDB, AOF ?
레디스는 주로 캐시로 사용되기 때문에 기본적으로 손실되어도 무방한 데이터를 기록해야 하는데, 하지만 실제 서비스를 운영하다보면 캐시라 할지라도 데이터가 손실되었을 때, 서비스 지연이 발생하거나 장애 상황으로 이어질 수 있기때문에 다음과 같은 옵션을 제공한다.
- RDB (Redis Database)
- 메모리에 있는 데이터 전체에서 스냅샷을 작성하고, 이를 디스크로 저장하는 방식
- 스냅샷 이후 변경된 데이터는 복구할 수 없기 때문에 사용 시 주의해야 한다.
- 재난 복구 또는 복제에 주로 사용된다.
- AOF (Append Only File)
- 데이터가 변경되는 이벤트가 발생하면 모두 로그에 저장하는 방식
- 모든 데이터 변경 기록들을 보관하므로 최신 데이터 정보를 백업 가능하다.
- RDB 방식에 비해 데이터 유실량이 적다. 하지만 Write 작업을 다시 적용하기 때문에 로딩 속도가 느리다.
서비스에 적합한 방식을 택해서 사용해야 한다. Redis에서는 영속성 옵션을 사용하지 않거나 두가지 옵션을 각각 사용하거나 두가지 옵션을 모두 사용할 수 있다. 일반적으로 특정 시간마다 RDB 스냅샷을 생성하고, 그 이후에 변경되는 데이터는 AOF로 백업하는 방식으로 RDB와 AOF를 조합하여 데이터를 백업한다고 한다.
레디스 동작
Redis는 명령들이 이벤트 루프 방식으로 처리된다. 클라이언트가 실행한 명령을 event queue에 적재하고, 싱글 스레드로 하나씩 처리하는 방식이다. 메모리를 사용하기 때문에 싱글 스레드로 데이터를 빠르게 처리할 수 있다. 따라서 컨텍스트 스위칭이 발생하지 않고 데드락이 발생하지 않는다는 장점이 있다. 하지만 오버헤드가 큰 명령어를 처리한다면 다른 명령들의 응답 속도가 길어질 수 있다는 단점이 있다.
1-2. 캐시 패턴
캐싱을 진행할 때는 다양한 패턴들이 존재하며, 서비스의 요구사항과 성능에 따라 적절히 사용해야 한다. 주로 대표적으로 사용되는 패턴은 Cache-Aside, Write-Through, Write-Behind가 있다.
1. Cache-Aside 패턴
클라이언트 요청을 조회할 때, 애플리케이션에서 캐시를 조회하여 cache hit인 경우 그대로 캐시를 사용해 요청을 처리하고, cache miss인 경우 원본 스토리지에서 데이터를 조회하여 캐싱한 뒤 데이터를 반환하는 방식이다. 코드가 간단하고 조회 성능을 높일 수 있지만 일관성을 보장하기 위해 데이터 만료 시간 설정에 주의해야 한다.
2, Write-Through 패턴
클라이언트 요청을 저장할 때, 애플리케이션에서 캐시와 원본 스토리지에 동시에 기록하는 방식으로, 모든 쓰기 요청이 캐시에 반영되므로 일관성이 높아진다. 하지만 쓰기 작업이 빈번한 경우 부하가 생길 수 있다.
3. Write-Behind 패턴
데이터가 변경되면 먼저 캐시에만 저장하고 원본 데이터 저장소에는 비동기적으로 업데이트하는 방식으로, 쓰기 성능은 향상되지만 원본 스토리지로의 데이터 반영이 지연될 수 있어 일관성 문제가 생길 수 있다.
이러한 캐시 패턴은 데이터의 최신성, 일관성 및 시스템의 성능을 보장하기 위해 적절히 사용해야 한다. 또한, 제한된 메모리를 어떻게 효율적으로 사용할 건지에 대한 캐시 전략도 신경써줘야 한다.
2. Redis 데이터 타입
Redis에는 다양한 데이터 타입을 제공한다. 일반적으로 콜론을 이용해 의미별로 구분하고, 데이터가 없다는 것을 null이 아닌 nil로 표현한다.
Strings
- 문자열, 숫자, JSON string 등을 저장한다.
- Redis는 별도의 integer 타입없이 string으로 숫자를 저장한다.
SET,MSET- 값을 저장할 때 사용
- 단일 key-value를 저장할 때, 다중 key-value를 저장할 때 사용
INCR,INCRBY- 숫자 형태의 더하기 빼기 연산 시 사용
- increase, increase by의 약자로 1을 더할 때, 특정 수를 더할 때 사용
Lists
- String을 LinkedList로 저장한다. 그 중에서도 Doubly LinkedList이다.
LPUSH,RPUSH,RPOP,LPOP- LPUSH, RPOP을 통해 Queue를 구현
- LPUSH, LPOP을 통해 Stack을 구현
LRANGE- 인덱스를 이용해 다수의 아이템 조회 가능
- 인덱스는 왼쪽부터 카운팅하면 0부터 시작하여 점차 증가, 오른쪽부터 카운팅하면 -1부터 점차 감소
LTRIM- 원하는 데이터만 남기고 싶을 때 사용
- 예를들어,
LTRIM queue 0 0은 가장 마지막에 추가된 아이템만 남기고 나머지는 모두 삭제한다.
Sets
- 순서가 보장되지 않으며, 유니크한 값을 저장한다.
SADD,SMEMBERS- 데이터 추가, set의 모든 멤버를 출력
SADD use:1:fruits apple banana orange orange를 넣어도 orange는 중복되어 저장되지 않는다.
SCARD- set의 카디널리티(고유한 아이템의 개수)를 출력
SISMEMBER- 특정 아이템이 set에 포함되었는지 확인
SINTER,SDIFF,SUNION- 교집합, 차집합, 합집합
SINTER user:1:fruits user:2:fruits는 유저1과 유저2가 공통으로 좋아하는 과일을 출력SDIFF user:1:fruits user:2:fruits는 유저1은 좋아하지만 유저2는 안좋아하는 과일
Hashes
- key - {field: value} 구조를 갖는 데이터 타입
HSET,HGET,HMGET- 하나의 해시에 다수의 field-value를 저장
- 하나의 해시에서 field를 통해 값 조회
- 여러 field 조회
HINCRBY- 해시의 특정 field의 특정 수를 더하는 것
Sorted Sets
- 유니크한 string을 연관된 score를 통해 정렬된 집합(Set의 기능 + scroe 속성 저장)
- score에 따라 정렬을 유지한다. score가 동일하면 사전 순으로 정렬
ZADD,ZRANGE,ZRANKZRANK는 해당 아이템의 랭킹을 반환한다. (0부터 시작)REV WITHSCORES키워드를 추가하면 역순 + 스코어와 함께 출력
Streams
- 이벤트성 로그를 저장할 때 사용하는 타입
XADD,XRANGE- 스트림에 엔트리를 추가, 다수의 메세지를 조회
- 엔트리를 추가할 때 key뒤에 ‘*’ 옵션을 주면 자동으로 유니크한 아이디가 할당된다.
Bitmaps
- 인터페이스 중 하나로, String을 활용해 비트 연산을 사용할 수 있도록 함
- 최대 42억개 binary 데이터를 표현할 수 있다. (2^32)
- 매우 적은 메모리를 사용해 데이터를 저장할 수 있다.
GETBIT- 해당 비트의 값 조회
BITOP- 비트 연산자 계산 (
AND: 뒤에서 모든 결과에 1인 애들만 출력) - 비트맵 결과를 새로운 비트맵으로 생성하기 때문에 이를 지정해줘야 한다. (
result)
- 비트 연산자 계산 (
- 출석체크 같은 기능에 사용할 수 있다.
HyperLogLog
- 집합의 카디널리티를 추정할 때 사용
- 멤버의 값을 해싱하여 버킷 단위로 분류해서 저장한다. 따라서 카디널리티를 일정하게 계산할 수 있다.
- 실제 값을 저장하지 않기 때문에, 적은 메모리로 카디널리티를 계산할 수 있다.
- 모든 아이템을 출력해야 하는 경우 활용할 수 없다.
BloomFilter
- 요소가 집합 안에 포함되었는지 확인할 수 있는 확률형 자료 구조
- HyperLogLog와 마찬가지로, 정확성을 일부 포기하고 저장공간을 효율적으로 사용할 수 있다.
- 실제 값을 저장하지 않기 때문에 적은 메모리를 사용한다.
- 저장원리
- 값을 해싱하여 여러 개의 해시 키를 만들어내고, 키에 해당하는 위치를 블룸필터에 표시한다. 이후에 어떤 아이템이 존재하는지 확인할 때, 키에 대한 블룸필터 위치를 확인한다.
- False Positive
- 데이터가 집합에 포함되지 않은데 포함되었다고 잘못 예측하는 경우가 있다. 사용전에 이를 반드시 인지하고 있어야 한다. (but, 있는데 없다고 하는 경우는 없다)
BF.MADD,BF.EXISTS- 데이터 추가, 존재 여부 확인
블룸 필터를 사용하려면 모듈을 설치해야 한다. 따라서 실제 redis에 설치하지 않고, docker로 redis/redis-stack-server를 포트 63790번으로 실행시키고, 터미널에 redis-cli -p 63790을 실행해 블룸 필터를 사용했다.
특수 명령어
EXPIRE: 데이터를 특정시간 이후에 만료 시키는 기능. 만료되자마자 삭제하지 않고, 나중에 백그라운드 태스크에 의해 주기적으로 삭제된다.TTL: 남은 만료시간 확인SETEX: 데이터를 저장하는 동시에 만료 시간 설정SET NX,SET XX: NN은 해당 key가 존재하지 않은 경우에만 set, XX는 해당 key가 존재하는 경우에만 setPUBLISH,SUBSCRIBE: pub/sub 동작
MULTI,DISCARD,EXEC: 트랜잭션 기능. 각 트랜잭션 시작, 롤백, 커밋
이 외에도 다양한 타입이 존재한다.
Understand Redis data types
Overview of data types supported by Redis
redis.io
3. 활용 및 예시
- 분산락 :
SET NX사용. 공유 자원을 표현할 수 있는 이름을 통해 락의 키를 설정하고, NX 옵션을 통해 해당 키가 존재하지 않은 경우에만 락을 획득하여 작업을 실행 - 유저 접속 상태 :
Bitmap사용. 현재 시간의 분을 기준으로 key 생성해서 해다 유저가 서버와 통신을 주고받고 있는 경우에 비트값을 1로 업데이트하고, 이후 통신하고 있지 않으면 비트값이 업데이트 하지 않고 유저의 상태를 오프라인으로 표시 - 방문자 확인 :
HyperLogLog사용. 방문자 수를 대략적으로 추정하는 경우. 예를 들어, 유저의 id로 카운팅하고 PFCOUNT를 통해 카디널리티 조회 - 중복 요청 방지 :
BloomFilter사용. 이벤트 데이터를 기준으로 해싱하고, 이벤트 발생 시간에 따라 고유한 id를 통해 저장. 이후에 중복 요청이 실행된다면 id를 기준으로 블룸필터 조회하고, 이미 존재한다면 false positive일 수도 있기 때문에 원본 스토리지를 한 번 더 조회하고 데이터를 처리 - 채팅 및 메시징 :
Pub/Sub사용. - 대기열 :
List사용
4. 주의점
대부분의 레디스 명령어는 O(1)의 시간복잡도를 갖지만, 일부 명령어의 경우 O(N)이니 주의해야 한다. 특히 레디스는 단일 스레드에서 모든 요청을 순차적으로 처리하기 때문에, 특정 명령으로 인해 전체 애플리케이션의 성능을 저하시킬 수도 있다.
O(N) 명령어
KEYS *SMEMBERSHGETALLSORT
5. 마무리
최근 프로젝트에 Redis를 적용하면서 캐싱 기술을 적용하는 것이 서비스를 개발하는데 큰 도움이 된다는 것을 알게 되었다. 이번 학습을 통해 레디스에 장점과 활용 사례를 알게되었고, 캐싱을 적용하는 것도 중요하지만 캐시를 어떻게 관리하는지도 주의해야 한다는 것을 깨닫게 되었다. 아직 실무에서는 사용해보지 못했지만, 이런 데이터 타입이 존재하고 캐싱을 왜 사용하는지에 대해 이해하게 되어서, 추후 개발에서는 이러한 기술에 대해 신중히 고민하고 도입하며 개발해야 겠다.
참고자료 😃
https://velog.io/@banggeunho/레디스Redis-알고-쓰자.-정의-저장방식-아키텍처-자료구조-유효-기간
https://www.inflearn.com/course/실전-redis-활용
https://aws.amazon.com/ko/elasticache/what-is-redis/
https://redis.io/docs/latest/develop/data-types/
https://medium.com/@mmoshikoo/cache-strategies-996e91c80303
'DB' 카테고리의 다른 글
| [DB] JDBC, DBCP (+Connection, Connection Pool) (0) | 2024.05.24 |
|---|---|
| [DB] B-Tree, B+Tree - DB Index (0) | 2024.04.18 |
| [DB] NoSQL (NotOnly SQL) (1) | 2024.03.28 |
| [DB] 데이터베이스 정규화 (Normalization) (1) | 2024.03.26 |
| [DB] 트랜잭션 격리수준 (Transaction Isolation) (0) | 2024.03.15 |