
SQL(Structured Query Language)은 관계형 데이터베이스에서 데이터를 조회, 수정, 삭제하는 등 RDBMS를 조작하는데 사용되는 언어이다. NoSQL은 Not Only SQL를 뜻하며 관계형 데이터베이스 모델과는 다른 형태의 데이터를 저장 및 관리하는 방식을 제공한다. NoSQL 데이터베이스에서도 데이터를 관리하고 조작하는데 사용되는 특정 언어가 존재하며, 다양한 데이터 모델을 가지고 있다.
1. 탄생
2000년대에 들어서 인터넷의 발전과 SNS 서비스들이 활성화되면서 효율적으로 대규모 데이터를 저장하고 조회하는 기술이 요구됐다. RDB는 정형화된 데이터를 저장하기 때문에 복잡하고 한정된 데이터를 저장하는데는 유용했지만, 이런 대규모 데이터를 저장하는데 어려움이 있었다.

RDB의 한계
- 유연한 확장성 부족
- 설계된 데이터베이스 스키마에 컬럼 추가나 수정 등의 작업이 필요하게 된다면, 이미 존재하는 튜플들에 추가된 컬럼에 대한 데이터를 모두 변경해줘야 하므로 DB 서버에 부담이 생긴다.
- 복잡한 JOIN 연산에 대해 READ 성능 하락
- RDB는 중복된 데이터를 제거하기 위해 정규화를 진행해 여러 테이블로 나눠진다. 나눠진 데이터를 조회하는데 복잡한 JOIN연산이 발생해 조회 성능이 떨어진다.
- Scale-Out에 유연하지 않음
- RDB는 사용자가 많아져 DB 서버에 부하가 생기면 scale-up하는 방식으로 서버의 성능을 업그레이드 시킨다. 부하가 생길 때마다 scale-up 해줘야 한다.
- RDB는 애초에 scale-out을 염두에 두고 설계되지 않았다. 관계형 모델과 트랜잭션의 연산 등을 유지하면서 분산 서버에서 RDB를 조작하는 것은 어렵다.
- ACID 성질의 트레이드 오프
- ACID를 보장하려다 보니 DB서버의 성능에 어느 정도 영향을 미치게 된다.
⇒ 따라서 비정형 데이터 형태로 쉽게 담아서 저장하고 처리할 수 있는 NoSQL이 관심을 받게 됐고, 해당 기술이 발전하게 되었다.
2. NoSQL 특징
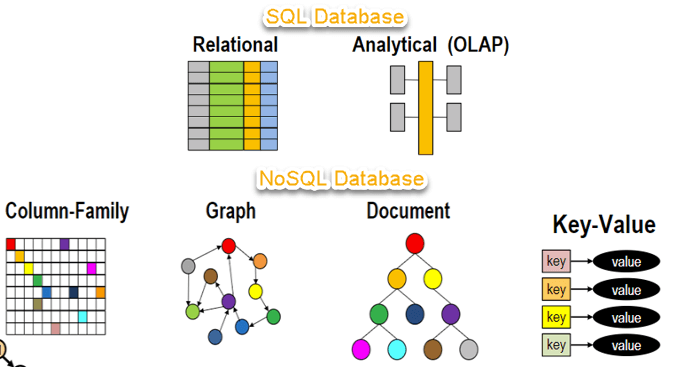
- 데이터 간의 관계를 정의하지 않는다.
- RDBMS에서는 데이터들 간의 관계를 FK 등으로 정의하고 이를 이용해 JOIN 연산으로 관계형 연산을 한다면, NoSQL은 데이터 간의 관계를 정의하지 않고 JOIN 없이 데이터를 조회한다.
- 대용량 데이터를 저장할 수 있다.
- 대용량 데이터의 읽기와 쓰기에 강점이 있다.
- 분산형 구조 (Scale-Out)
- NoSQL은 서버 수십 대를 연결해 데이터를 저장 및 처리하는 구조이다.
- 데이터를 여러 대 서버에 분산해 저장하고 데이터를 상호 복제해, 특정 서버에서 장애가 발생하더라도 데이터 유실이나 서비스 중지가 없도록 한다.
- 유동적인 스키마
- 스키마의 컬럼은 데이터를 저장할 때마다 다른 이름과 다른 데이터 타입을 가질 수 있다.
CAP 이론
NoSQL은 분산형 구조를 띄고 있기 때문에 분산 시스템 성질인 CAP 이론을 따른다.
CAP 이론은 일관성, 가용성, 분할 허용성이라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것을 불가능하다는 이론으로, 세가지 중 두 가지를 충족하려면 나머지 하나는 희생됨을 의미합니다.
- 일관성 (Consistency) : 분산된 노드 중 어느 노드로 접근하더라도 데이터 값이 같아야 한다. (ACID의 C와 약간 의미가 다르다)
- 가용성 (Availability) : 클러스터링된 노드 중 일부 노드에 장애가 발생해도, 정상적으로 응답이 가능함을 보장한다.
- 분산 허용성 (Partition Tolerance) : 클러스터링 노드 간에 통신하는 네트워크가 장애를 겪더라도 정상적으로 서비스를 수행한다.
따라서 CA, AP, CP시스템으로 나뉠 수 있지만, 네트워크 장애는 피할 수 없는 일로 여겨지므로 분산 시스템은 P를 감내할 수 있도록 설계되어야 한다.
3. NoSQL 단점
- RDB의 특징이었던 ACID의 성질을 잃는다.
- 스키마가 고정되어 있지 않으므로, 개발자가 데이터에 대한 무결성 검증을 제대로 해야 한다.
- 데이터가 여러 *컬렉션에 중복되어 있기 때문에 데이터를 수정하는 경우, 모든 컬렉션에서 수행해야한다.
=> ^RDB와 NoSQL의 장단점을 고려하여, 개발하는 서비스 특징에 적합한 데이터베이스를 선택해야 한다.^
* 컬렉션 (Collection) ?
NoSQL에서는 일반적으로 문서 지향 데이터 모델을 사용하는데, 컬렉션은 문서 지향 데이터 모델에서 문서(document)들의 그룹을 나타내는 개념이다. NoSQL에서는 비슷한 유형의 문서들을 같은 컬렉션에 넣어 저장하며, 다른 구조의 데이터를 같은 컬렉션에 추가할 수 있다.
(NoSQL에서 컬렉션-문서는 RDB에서 테이블-레코드에 대응된다)
4. NoSQL 도입 서비스
NoSQL 사용을 고려해야 하는 서비스는 다음과 같다.
- 정확한 데이터 구조를 알 수 없거나 변경, 확장 가능성이 있는 경우
- 조회는 많지만, 변경은 드문 경우
- 대량의 데이터를 다뤄야해서 데이터베이스를 수평적으로 확장해야 하는 경우
ACID 성질을 준수해야 하는 은행 거래 시스템에 NoSQL을 도입하는 건 위험하다. 또 스키마의 변경이 변경될 여지가 없고 해당 스키마 속성을 따르는 정형화된 데이터를 저장해야 한다면 NoSQL 보다는 RDBMS를 이용하는 것이 좋을 것이다. 보통 실무에서는 어느 하나만 사용하지 않고, RDB와 NoSQL을 혼합하여 사용한다고 한다.
5. 데이터 모델
NoSQL은 데이터 모델이 다양하다. 다음 유형들 외에도 다양한 데이터 모델이 존재하며 계속해서 새로운 모델이 생겨나고 있다.

Key-Value Database
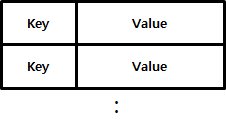
가장 기본적인 모델로 key-value 쌍으로 저장되는 방식이다. 고유한 key에 하나의 value를 가지고 있는 형태이다. value는 문자열, 숫자 처럼 단순한 값이 일반적이지만, 리스트나 JSON 같은 구조화된 값도 가질 수 있다.
ex) Redis, Dynamo DB 등
Document Database

Key-Value Database의 확장된 형태이다. key-value에 데이터를 저장하는 구조는 동일하나, 저장되는 value의 데이터 타입이 Document이다. 여기서 Document는 XML, JSON과 같이 구조화된 데이터 타입을 말한다.
ex) MongoDB, CoughDB 등
Column-Family Database
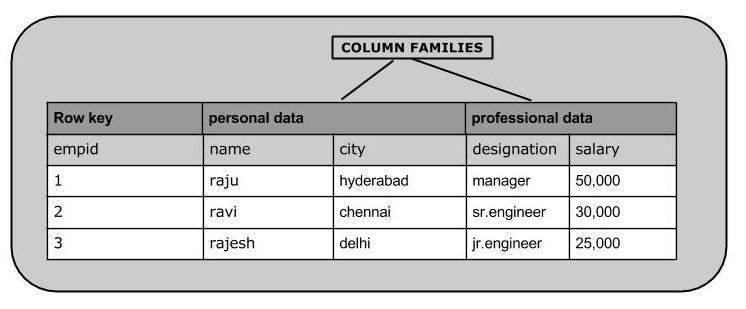
대용량 데이터의 읽기와 쓰기 및 고가용성을 위해 설계되었다. 데이터는 서로 관련된 컬럼 그룹인 컬럼 패밀리에 저장된다. Column과 Row 같이 RDB와 동일한 용어를 사용하여 스키마를 정의한다.
그림을 보면 name, city와 같이 관련된 컬럼들은 personal data로 묶는데, personal data 컬럼을 Column Family라고 한다.
ex) HBase, Cassandra, GCP BigTable 등
Graph Database

데이터를 노드(Node)로 표현하고 노드 사이의 관계를 엣지(Edge)로 표현하면서 그래프 개념을 활용한다. 데이터들의 관계를 중요시해서 저장된 데이터들이 Edge로 직접 연결될 수 있고 데이터 질의 시 특정 노드와 연관된 데이터들을 쉽게 가져올 수 있다.
ex) Neo4j, BlazeGraph 등
참고자료 😃
https://code-lab1.tistory.com/53
https://www.samsungsds.com/kr/insights/1232564_4627.html
https://www.youtube.com/watch?v=sqVByJ5tbNA
https://www.youtube.com/watch?v=Q_9cFgzZr8Q&t=281s
https://www.whatap.io/ko/blog/173/
https://gyoogle.dev/blog/computer-science/data-base/SQL%20&%20NOSQL.html
'DB' 카테고리의 다른 글
| [DB] JDBC, DBCP (+Connection, Connection Pool) (0) | 2024.05.24 |
|---|---|
| [DB] B-Tree, B+Tree - DB Index (0) | 2024.04.18 |
| [DB] 데이터베이스 정규화 (Normalization) (1) | 2024.03.26 |
| [DB] 트랜잭션 격리수준 (Transaction Isolation) (0) | 2024.03.15 |
| [DB] 트랜잭션 (Transaction) (0) | 2024.03.10 |
SQL(Structured Query Language)은 관계형 데이터베이스에서 데이터를 조회, 수정, 삭제하는 등 RDBMS를 조작하는데 사용되는 언어이다. NoSQL은 Not Only SQL를 뜻하며 관계형 데이터베이스 모델과는 다른 형태의 데이터를 저장 및 관리하는 방식을 제공한다. NoSQL 데이터베이스에서도 데이터를 관리하고 조작하는데 사용되는 특정 언어가 존재하며, 다양한 데이터 모델을 가지고 있다.
1. 탄생
2000년대에 들어서 인터넷의 발전과 SNS 서비스들이 활성화되면서 효율적으로 대규모 데이터를 저장하고 조회하는 기술이 요구됐다. RDB는 정형화된 데이터를 저장하기 때문에 복잡하고 한정된 데이터를 저장하는데는 유용했지만, 이런 대규모 데이터를 저장하는데 어려움이 있었다.
RDB의 한계
- 유연한 확장성 부족
- 설계된 데이터베이스 스키마에 컬럼 추가나 수정 등의 작업이 필요하게 된다면, 이미 존재하는 튜플들에 추가된 컬럼에 대한 데이터를 모두 변경해줘야 하므로 DB 서버에 부담이 생긴다.
- 복잡한 JOIN 연산에 대해 READ 성능 하락
- RDB는 중복된 데이터를 제거하기 위해 정규화를 진행해 여러 테이블로 나눠진다. 나눠진 데이터를 조회하는데 복잡한 JOIN연산이 발생해 조회 성능이 떨어진다.
- Scale-Out에 유연하지 않음
- RDB는 사용자가 많아져 DB 서버에 부하가 생기면 scale-up하는 방식으로 서버의 성능을 업그레이드 시킨다. 부하가 생길 때마다 scale-up 해줘야 한다.
- RDB는 애초에 scale-out을 염두에 두고 설계되지 않았다. 관계형 모델과 트랜잭션의 연산 등을 유지하면서 분산 서버에서 RDB를 조작하는 것은 어렵다.
- ACID 성질의 트레이드 오프
- ACID를 보장하려다 보니 DB서버의 성능에 어느 정도 영향을 미치게 된다.
⇒ 따라서 비정형 데이터 형태로 쉽게 담아서 저장하고 처리할 수 있는 NoSQL이 관심을 받게 됐고, 해당 기술이 발전하게 되었다.
2. NoSQL 특징
- 데이터 간의 관계를 정의하지 않는다.
- RDBMS에서는 데이터들 간의 관계를 FK 등으로 정의하고 이를 이용해 JOIN 연산으로 관계형 연산을 한다면, NoSQL은 데이터 간의 관계를 정의하지 않고 JOIN 없이 데이터를 조회한다.
- 대용량 데이터를 저장할 수 있다.
- 대용량 데이터의 읽기와 쓰기에 강점이 있다.
- 분산형 구조 (Scale-Out)
- NoSQL은 서버 수십 대를 연결해 데이터를 저장 및 처리하는 구조이다.
- 데이터를 여러 대 서버에 분산해 저장하고 데이터를 상호 복제해, 특정 서버에서 장애가 발생하더라도 데이터 유실이나 서비스 중지가 없도록 한다.
- 유동적인 스키마
- 스키마의 컬럼은 데이터를 저장할 때마다 다른 이름과 다른 데이터 타입을 가질 수 있다.
CAP 이론
NoSQL은 분산형 구조를 띄고 있기 때문에 분산 시스템 성질인 CAP 이론을 따른다.
CAP 이론은 일관성, 가용성, 분할 허용성이라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것을 불가능하다는 이론으로, 세가지 중 두 가지를 충족하려면 나머지 하나는 희생됨을 의미합니다.
- 일관성 (Consistency) : 분산된 노드 중 어느 노드로 접근하더라도 데이터 값이 같아야 한다. (ACID의 C와 약간 의미가 다르다)
- 가용성 (Availability) : 클러스터링된 노드 중 일부 노드에 장애가 발생해도, 정상적으로 응답이 가능함을 보장한다.
- 분산 허용성 (Partition Tolerance) : 클러스터링 노드 간에 통신하는 네트워크가 장애를 겪더라도 정상적으로 서비스를 수행한다.
따라서 CA, AP, CP시스템으로 나뉠 수 있지만, 네트워크 장애는 피할 수 없는 일로 여겨지므로 분산 시스템은 P를 감내할 수 있도록 설계되어야 한다.
3. NoSQL 단점
- RDB의 특징이었던 ACID의 성질을 잃는다.
- 스키마가 고정되어 있지 않으므로, 개발자가 데이터에 대한 무결성 검증을 제대로 해야 한다.
- 데이터가 여러 *컬렉션에 중복되어 있기 때문에 데이터를 수정하는 경우, 모든 컬렉션에서 수행해야한다.
=> RDB와 NoSQL의 장단점을 고려하여, 개발하는 서비스 특징에 적합한 데이터베이스를 선택해야 한다.
* 컬렉션 (Collection) ?
NoSQL에서는 일반적으로 문서 지향 데이터 모델을 사용하는데, 컬렉션은 문서 지향 데이터 모델에서 문서(document)들의 그룹을 나타내는 개념이다. NoSQL에서는 비슷한 유형의 문서들을 같은 컬렉션에 넣어 저장하며, 다른 구조의 데이터를 같은 컬렉션에 추가할 수 있다.
(NoSQL에서 컬렉션-문서는 RDB에서 테이블-레코드에 대응된다)
4. NoSQL 도입 서비스
NoSQL 사용을 고려해야 하는 서비스는 다음과 같다.
- 정확한 데이터 구조를 알 수 없거나 변경, 확장 가능성이 있는 경우
- 조회는 많지만, 변경은 드문 경우
- 대량의 데이터를 다뤄야해서 데이터베이스를 수평적으로 확장해야 하는 경우
ACID 성질을 준수해야 하는 은행 거래 시스템에 NoSQL을 도입하는 건 위험하다. 또 스키마의 변경이 변경될 여지가 없고 해당 스키마 속성을 따르는 정형화된 데이터를 저장해야 한다면 NoSQL 보다는 RDBMS를 이용하는 것이 좋을 것이다. 보통 실무에서는 어느 하나만 사용하지 않고, RDB와 NoSQL을 혼합하여 사용한다고 한다.
5. 데이터 모델
NoSQL은 데이터 모델이 다양하다. 다음 유형들 외에도 다양한 데이터 모델이 존재하며 계속해서 새로운 모델이 생겨나고 있다.
Key-Value Database
가장 기본적인 모델로 key-value 쌍으로 저장되는 방식이다. 고유한 key에 하나의 value를 가지고 있는 형태이다. value는 문자열, 숫자 처럼 단순한 값이 일반적이지만, 리스트나 JSON 같은 구조화된 값도 가질 수 있다.
ex) Redis, Dynamo DB 등
Document Database
Key-Value Database의 확장된 형태이다. key-value에 데이터를 저장하는 구조는 동일하나, 저장되는 value의 데이터 타입이 Document이다. 여기서 Document는 XML, JSON과 같이 구조화된 데이터 타입을 말한다.
ex) MongoDB, CoughDB 등
Column-Family Database
대용량 데이터의 읽기와 쓰기 및 고가용성을 위해 설계되었다. 데이터는 서로 관련된 컬럼 그룹인 컬럼 패밀리에 저장된다. Column과 Row 같이 RDB와 동일한 용어를 사용하여 스키마를 정의한다.
그림을 보면 name, city와 같이 관련된 컬럼들은 personal data로 묶는데, personal data 컬럼을 Column Family라고 한다.
ex) HBase, Cassandra, GCP BigTable 등
Graph Database
데이터를 노드(Node)로 표현하고 노드 사이의 관계를 엣지(Edge)로 표현하면서 그래프 개념을 활용한다. 데이터들의 관계를 중요시해서 저장된 데이터들이 Edge로 직접 연결될 수 있고 데이터 질의 시 특정 노드와 연관된 데이터들을 쉽게 가져올 수 있다.
ex) Neo4j, BlazeGraph 등
참고자료 😃
https://code-lab1.tistory.com/53
https://www.samsungsds.com/kr/insights/1232564_4627.html
https://www.youtube.com/watch?v=sqVByJ5tbNA
https://www.youtube.com/watch?v=Q_9cFgzZr8Q&t=281s
https://www.whatap.io/ko/blog/173/
https://gyoogle.dev/blog/computer-science/data-base/SQL%20&%20NOSQL.html
'DB' 카테고리의 다른 글
| [DB] JDBC, DBCP (+Connection, Connection Pool) (0) | 2024.05.24 |
|---|---|
| [DB] B-Tree, B+Tree - DB Index (0) | 2024.04.18 |
| [DB] 데이터베이스 정규화 (Normalization) (1) | 2024.03.26 |
| [DB] 트랜잭션 격리수준 (Transaction Isolation) (0) | 2024.03.15 |
| [DB] 트랜잭션 (Transaction) (0) | 2024.03.10 |