
JDBC와 DBCP에 대해 학습하고, DBCP 옵션들에 대해 알아보자 ❕
JDBC와 DBCP 모두 데이터베이스와 상호작용하는데 사용되는 기술이다.
JDBC는 자바에서 데이터베이스에 접근하고 쿼리를 실행하기 위한 표준 API이고, DBCP는 데이터베이스 연결을 효율적으로 관리하고 성능을 최적화하기 위한 기술이다. JDBC 위에서 DBCP가 동작되는 형태이다.
특히 대규모 애플리케이션이나 높은 트래픽의 서비스에서는 DBCP 방식을 사용해 성능을 최적화하는 것이 중요한데, 왜 DBCP를 사용하는 것이며 어떤 설정값이 있는지 알아보려고 한다.
1. JDBC(Java DataBase Connectivity)
자바에서 데이터베이스에 접근하고 쿼리를 실행하기 위한 표준 API이다.
개발자가 JDBC API를 이용해 데이터베이스 관련 작업을 작성하면, JDBC API는 SQL문을 실행하고 결과를 조회할 수 있도록 한다. 따라서 데이터베이스 내부 동작 방식에 대해 신경쓰지 않아도 된다.
JDBC 드라이버는 여러 종류가 있으며, 각 DBMS에 맞게 설계되어 있다. 만약 데이터베이스로 MySQL을 사용하다가 Oracle로 변경한다면 JDBC 드라이버를 교체해주면 된다. (물론 쿼리 작성한 곳에서 약간의 문법 수정도 필요하다)
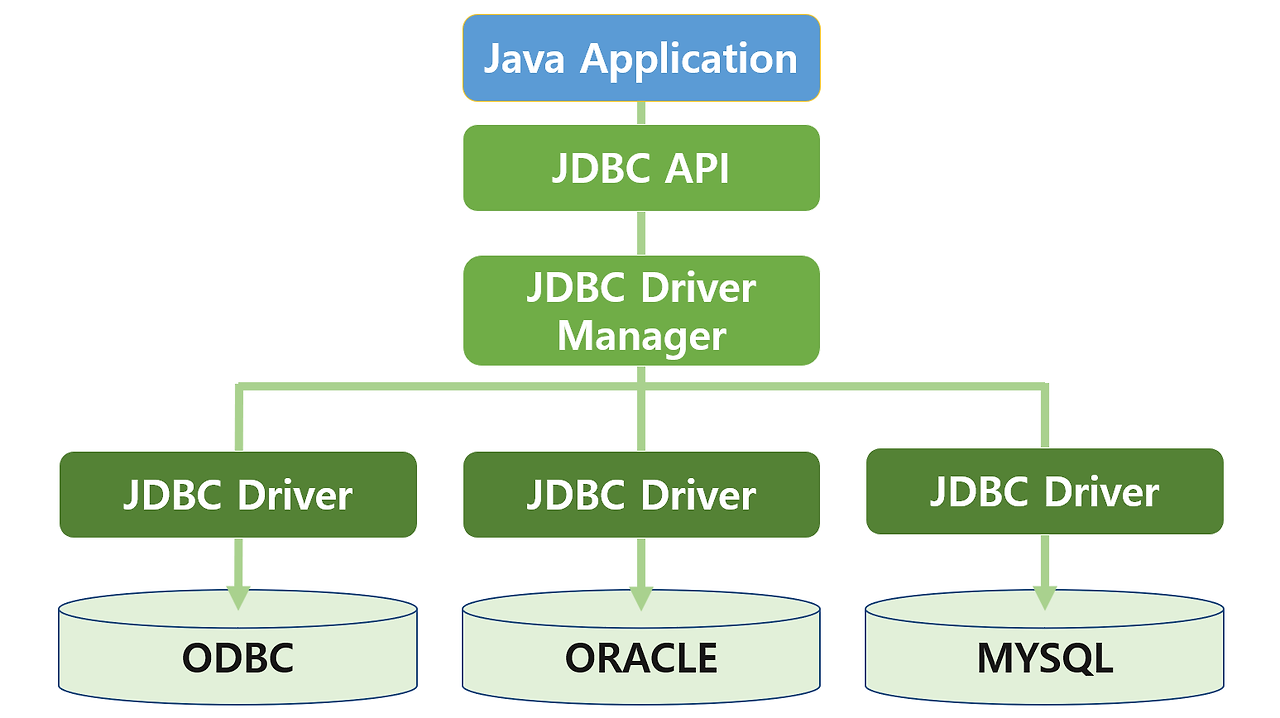
동작 흐름

Java 프로그램 → JDBC API → JDBC Driver → DB
JDBC API를 사용하기 위해서는 *JDBC Driver를 먼저 로딩한 후 데이터베이스와 연결한다.
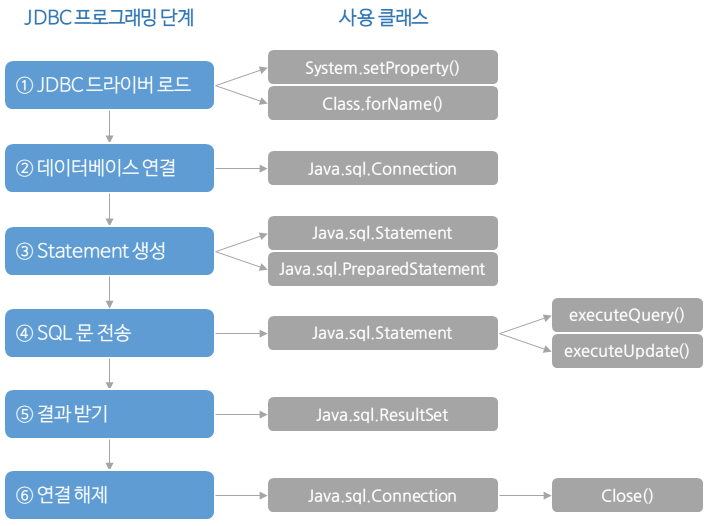
- JDBC 드라이버 로드
- DB 연결 (커넥션 객체 생성) -
DriverManager.getConnection() - SQL 쿼리 실행 - 쿼리 수행을 위한
PreparedStatement객체 생성,executeQuery()로 쿼리 실행 - 결과 처리 -
ResultSet객체에 결과를 받아옴 - 사용했던
ResultSet,PreparedStatement,Connection을 close
* JDBC Driver ?
데이터베이스와의 통신을 담당하는 인터페이스로, 각 DBMS에 맞는 JDBC 드라이버가 존재한다.
JDBC 드라이버는 자바 프로그램의 요청을 DBMS가 이해할 수 있는 형태로 변환해주고 처리한다.
JDBC 방식의 단점
일반적인 JDBC는 DB에 요청을 보낼 때마다 매번 DB 연결을 열고 닫는다. 이렇게 매 요청마다 DB 연결을 열고 닫는 방식을 JDBC 방식이라고 한다. ^JDBC 방식은 사람들이 많이 접속하는 서비스에서 계속 드라이버를 로드하고, 객체를 생성하기 때문에 비효율적으로 동작하기때문에 상용 서비스에서 사용하는 경우는 드물다.^ (보통 DB 연결 시 TCP 통신을 이용)
즉, 데이터베이스 연결이 반복적으로 열리고 닫히면서 성능 저하가 발생해 비효율적이다.
그래서 등장한 것이 DBCP이다. ^DBCP는 WAS 실행 시 미리 일정량의 DB 커넥션 객체를 생성하고 Pool이라는 공간에 저장해 재사용한다. DB 연결 요청이 있으면, Pool에서 커넥션 객체를 가져다 쓰고 반환한다.^
먼저 DBCP 방식에서 사용되는 개념인 Connection과 Connection Pool에 대해 알아보자
2. Connection & Connection Pool
Connection
- DB를 사용하기 위해 DB와 애플리케이션 간 통신을 할 수 있는 수단
- 네트워크 상의 연결 자체를 의미
Connection Pool
- 커넥션 객체를 저장하는 저장소
- 웹 컨테이너(WAS)가 실행되면서 일정량의 커넥션 객체를 미리 만들고 저장소에 보관해둔다. 클라이언트의 요청이 오면 미리 생성된 커넥션 객체를 빌려주고 해당 객체의 임무가 완료되면 다시 저장소에 반납한다.
3. DBCP (DataBase Connection Pool)
데이터베이스 커넥션을 재사용할 수 있도록 풀(Pool)로 관리하는 기술을 말한다.
웹 컨테이너가 실행되면 일정 개수만큼 DB 커넥션 객체를 생성해 Pool에 넣고, 필요할 때마다 가져다 쓰고 반납하는 방식이다. 이미 생성된 연결을 재사용하기 때문에 자원을 효율적으로 사용할 수 있고, 미리 만든 연결은 메모리 상에 등록해 놓기 때문에 사용자 요청 시 빠른 응답이 가능하다.
DBCP 종류로는 Apache Commons DBCP2, HikariCP, Tomcat JDBC Connection Pool 등이 있다. (Spring Boot 2.0 부터는 기본 커넥션 풀 라이브러리로 HikariCP를 제공한다)
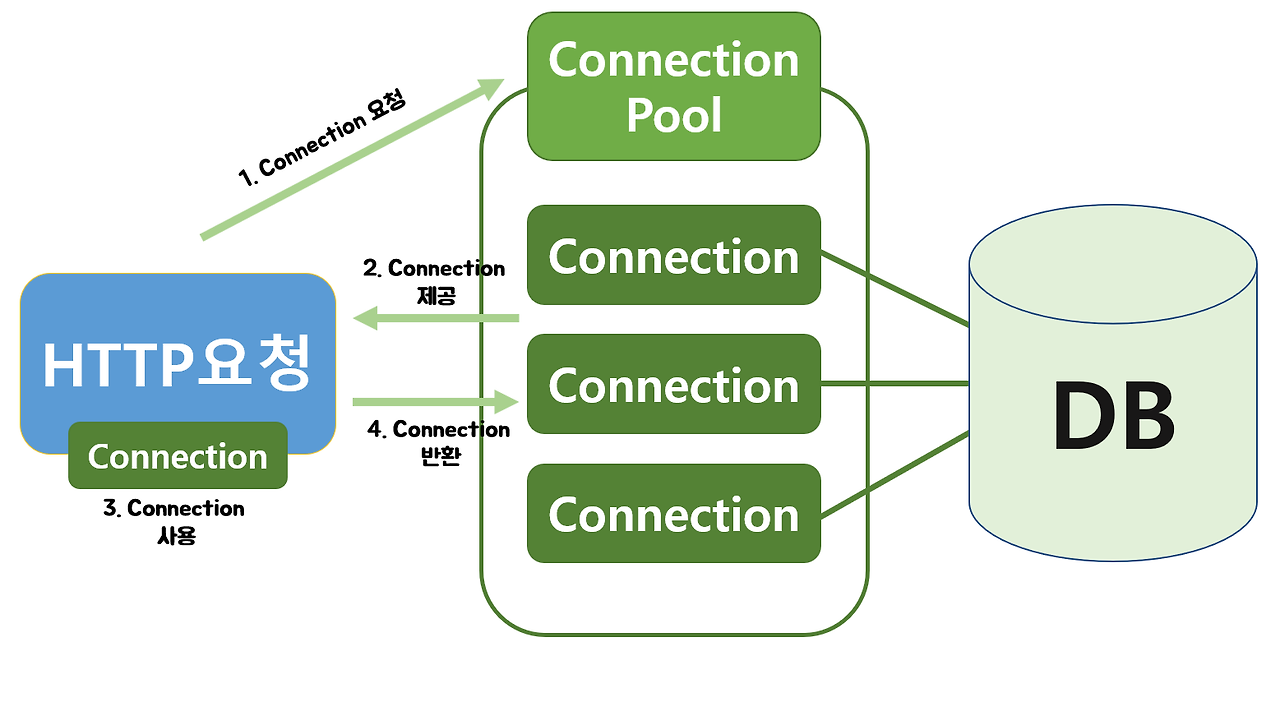
동작 흐름
- 웹 컨테이너(WAS)가 실행되면서 일정 개수의 Connection 객체를 미리 Pool에 생성
- DB 요청이 오면 Pool에 이미 생성된 Connection 객체를 가져다 쓰고, 다쓰면 Pool에 반환한다.
DBCP 방식은 자동으로 연결을 관리하므로 개발자의 부담이 줄어들고 코드의 복잡성을 줄여줄 수 있다. 실무에서는 커넥션 풀을 이용해 얻는 이점이 크기 때문에 기본으로 사용하는 것이 좋다.
+ JNDI (Java Naming and Directory Interface) ?
JDBC와 DBCP에 대해 자료를 찾아보니 JNDI라는 개념이 자주 등장한다.
JNDI는 디렉터리 서비스에서 제공하는 데이터와 객체를 발견하고 참고하기 위한 자바 API이다.
JNDI를 사용하면 DBCP 관련 설정을 서버의 디렉터리에 설정해 WAS 단에서 커넥션 관리를 할 수 있다. 이 경우 WAS에서 서버를 여러개 운영하는 경우, DBCP 설정을 한곳에서 설정할 수 있으며 설정값에 변경이 있을 경우 수정이 용이하다는 이점이 있다.
4. DBCP 옵션
각 DBCP마다 옵션을 설정하는 변수가 다르기 때문에 각 공식문서를 확인해야 한다.
여기서는 Spring에서 기본으로 사용하는 HkariCP에서 자주 사용되는 옵션들을 다음 링크를 참고해 일부 정리했다.
GitHub - brettwooldridge/HikariCP: 光 HikariCP・A solid, high-performance, JDBC connection pool at last.
光 HikariCP・A solid, high-performance, JDBC connection pool at last. - brettwooldridge/HikariCP
github.com
다음 옵션들은 Spring `application.properties` 및 `application.yml`로 설정할 수 있다.
- maximumPoolSize : Pool에서 유지할 수 있는 최대 커넥션 수 (default : 10)
- minimumIdle : Pool에서 유지할 최소 유휴 커넥션 수. maximumPoolSize와 동일하게 설정할 것을 권장 (default : 10)
- connectionTimeout : 커넥션을 얻기 위해 기다릴 수 있는 최대 시간. 이 때까지 커넥션을 얻지 못하면 예외가 발생한다. (default : 30,000 (30초))
- idleTimeout : Pool에서 유휴 상태 커넥션들의 유지될 수 있는 최대 시간. minimumIdle이 maximumPoolSize보다 작게 설정된 경우에만 이 값을 설정할 수 있다. (default : 600,000 (10분))
- maxLifetime : 커넥션의 최대 수명. 사용 중인 커넥션이 최대수명을 초과했어도, 종료된 후에 제거된다. (default : 180,000 (30분))
커넥션 풀을 크게 설정하면 클라이언트의 요청 대기 시간이 줄어든다. 하지만 그만큼 커넥션 객체가 많이 생성되기 때문에 메모리를 소모하게 된다. 반대로 커넥션 풀을 작게 설정하면 클라이언트의 요청 대기 시간이 길어진다. 따라서 요청량 따라 적당한 수의 커넥션 객체를 생성해줘야 한다.
Hikari CP 권장 옵션
Hikari CP의 공식 문서에는 다음과 같이 옵션을 설정할 것을 권장한다.
1. minimumIdle == maximumPoolSize
- minimumIdle(5개) < maximumPoolSize(10개)인 경우, 항상 5개의 커넥션을 동시에 사용하는 상황에서 1개의 커넥션이 추가로 요청된다면 커넥션이 생성되고, minimumIdle이 5이므로 1개의 커넥션에 대해서는 폐기하는 작업이 필요하다.
- mininumIdle > maximumPoolSize인 경우에도 마찬가지로 매번 커넥션을 생성하고 폐기하는 작업이 필요하다.
-> 따라서 커넥션을 매번 생성했다 닫는 비용이 발생할 수 있기 때문에 두 값을 동일하게 설정할 것을 권장한다.
2. PostgreSQL에서 제공한 공식. Hikari CP 공식문서에서 다른 전반적인 데이터베이스에 적용될 수 있는 공식이라고 제시하고 있다.
connections = ((core_count) * 2) + effective_spindle_count)- connections : 최대 커넥션 수
- core_count : 서버의 CPU 코어 수
- 최대 커넥션 수가 코어 수에 근접할수록 좋지만 CPU와 디스크/네트워크의 속도 차이로 인해 계수 2를 곱해준다.
- 속도 차이로 인해 스레드가 디스크와 같은 작업에서 블로킹되는 시간에 다른 스레드의 작업을 처리할 수 있는 여유가 생기기 때문
- effective_spindle_count : DB 서버가 관리할 수 있는 동시 I/O 요청 수
- 디스크 스핀들(spindle) 수
- 디스크가 16개 있는 경우, DB 서버는 동시에 16개의 I/O 요청을 처리할 수 있다.
3. Dead Lock을 피하기 위한 Connection Pool 공식.
pool size = Tn x (Cm - 1) + 1- Dead Lock을 피하기 위한 Connection Pool 공식.
- Tn : WAS의 전체 스레드 개수
- Cm : 하나의 스레드가 작업을 수행하기 위해 동시에 필요한 DB Connection 수
- 위 공식은 데드락이 발생하지 않을 최소값이다. 따라서 +1보다 조금 더 여유로운 최적의 값을 찾아내는 것이 좋다.
⇒ 위 세가지 공식을 참고하되, 테스트를 통해 각 시스템에 적절한 값을 찾는게 좋은 방법이다.
+ 3번 Dead Lock을 피하기 위한 Connection Pool 공식에 대하여
참고 우아한 형제들 기술블로그 - HikariCP Dead lock에서 벗어나기
데드락 발생 조건
- Thread-1이 필요한 커넥션 수 : 2개
- 현재 Pool Size : 1개
만약 Thread-1이 작업을 수행하기 위해 2개의 DB 커넥션이 필요하고, 현재 pool size는 1이라고 하자. 그럼 Thread-1이 작업을 수행하기 위해 Pool에서 커넥션 1개를 받아오는데, Thread-1은 아직 하나의 커넥션이 더 필요하므로 다른 스레드로부터 1개의 커넥션이 반납될 때까지 대기한다. Thread-1은 자기자신이 커넥션을 반납하는 것을 대기하는 상황이고, 데드락이 발생한다.
이제 공식을 사용해 해결해보자
pool size = Tn x (Cm - 1) + 1- 스레드 최대 개수 : 5개
- 하나의 스레드 당 필요한 커넥션 수 : 2개
- Pool Size = 5 x (2 - 1) + 1
스레드 최대 개수가 5이고, 동시에 필요한 커넥션 수가 2개라고 하자. 위 공식을 적용해보면, pool size는 6개이다. Thread-1~5까지 5개의 스레드가 동시에 커넥션을 요청해 하나씩 나눠가졌고, Thread-1이 남은 한개의 커넥션을 더 획득했다. Thread-1을 제외한 나머지 스레드들은 커넥션 객체를 얻기 위해 대기하고 있고, Thread-1은 로직을 처리한뒤 Pool에 커넥션을 반납한다. 그럼 Pool에 반납된 커넥션은 2개가 되고, 나머지 스레드 중 2개의 스레드가 커넥션을 획득해 로직을 처리할 수 있다. 나머지 스레드들에 대해서도 마찬가지이다.
공식에서 +1개의 커넥션이 데드락을 해결하는 핵심 key가 되는 것이다.
5. Spring 실습
application.properties
# == HikariCP SETTING ==
spring.datasource.hikari.maximum-pool-size=2
spring.datasource.hikari.connection-timeout=3000maximumPoolSize와 connectionTimeout값을 설정해준다.
Controller
@GetMapping("/test")
public void hikariTest() {
System.out.println("=== start!!! ===");
service.hikariTest()
System.out.println("=== finish!!! ===");
}컨트롤러로 요청이 들어오면 “=== start!!! ===”을 출력하고 서비스단 메서드를 요청한다.
Service
@Transactional(readOnly = true)
public void hikariTest() {
try {
System.out.println("=== sleep!!! ===");
Thread.sleep(10000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}서비스로 요청이 들어오면 "=== sleep!!! ==="을 출력하고 `Thread.sleep`으로 10초간 스레드를 정지시킨다.
(커넥션을 얻기 위해 `@Transactional` 어노테이션을 추가)
각 요청은 브라우저와 포스트맨으로 실행했다.
현재 Pool 사이즈는 2 이므로 두 요청이 모두 정상적으로 컨트롤러단의 “=== finish!!! ===”가 출력된다.
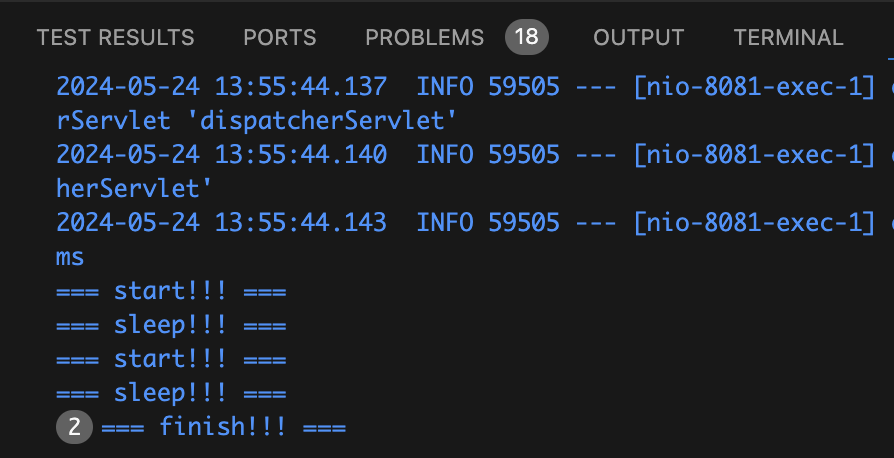
+ maximumPoolSize를 1로 바꾸면 어떻게 될까?
# == HikariCP SETTING ==
spring.datasource.hikari.maximum-pool-size=1
spring.datasource.hikari.connection-timeout=3000두 요청을 실행했을 때, Pool 사이즈는 1이므로 먼저 들어온 스레드가 커넥션을 얻고 10초간 정지한다. 그럼 다른 스레드는 커넥션을 얻지 못한채 대기하다가 connectionTimeout인 3초를 초과하기 때문에 예외가 발생할 것이다.
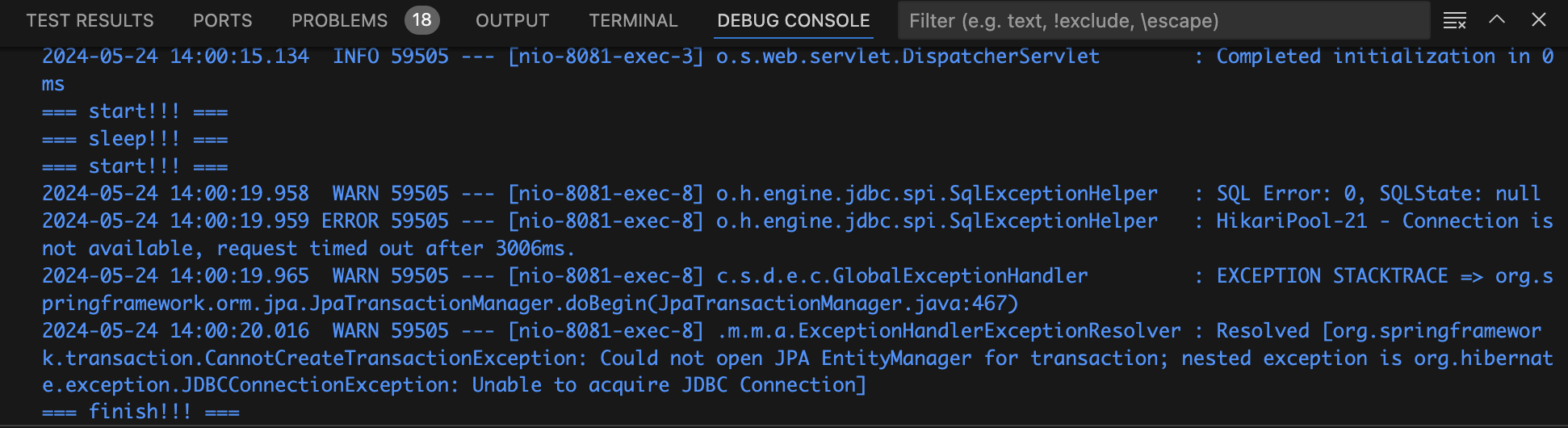
먼저 들어온 스레드가 10초간 대기상태에 들어가면, 다른 스레드는 대기하다가 connectionTimeout인 3초를 초과해 request timed out 예외가 발생한다.
6. 마무리
학생 때 만들었던 첫 웹 프로젝트에서 JDBC API를 직접 호출하는 DriverManager.getConnection(DBURL, DBName, DBPW), executeQuery() 같은 코드를 짰는데, 당시 try-catch문도 많이 사용하고 중복코드가 많았던 기억이 있다. 그때는 DBCP라는 것이 있는지도 몰랐고ㅎ 적은 트래픽 요청의 서비스라 이런 커넥션 관리 기술을 신경쓰지 못하고 오로지 로직 구현만 했던 것 같다.
이후 개발에서 Spring 프레임워크 + JPA를 사용하다보니 직접적으로 JDBC API를 사용하는 경우가 없었고, HikariCP 관련 설정도 기본값을 사용했었다. 이번 기회에 이런 기술들이 왜 생겨났고, 왜 필요한지에 대해 생각할 수 있었다. DB 관련 설정은 어떤 서비스에서나 중요한 요소이므로 추후 프로젝트를 설계할 때는 이런 설정값들을 신경써서 구현해야겠다.
참고자료 😃
https://adjh54.tistory.com/430
https://egg-stone.tistory.com/16
https://steady-coding.tistory.com/564#google_vignette
https://techblog.woowahan.com/2664/
https://techblog.woowahan.com/2663/
'DB' 카테고리의 다른 글
| [DB] Redis 개념과 데이터 타입 실습 (8) | 2024.11.04 |
|---|---|
| [DB] B-Tree, B+Tree - DB Index (0) | 2024.04.18 |
| [DB] NoSQL (NotOnly SQL) (1) | 2024.03.28 |
| [DB] 데이터베이스 정규화 (Normalization) (1) | 2024.03.26 |
| [DB] 트랜잭션 격리수준 (Transaction Isolation) (0) | 2024.03.15 |
JDBC와 DBCP에 대해 학습하고, DBCP 옵션들에 대해 알아보자 ❕
JDBC와 DBCP 모두 데이터베이스와 상호작용하는데 사용되는 기술이다.
JDBC는 자바에서 데이터베이스에 접근하고 쿼리를 실행하기 위한 표준 API이고, DBCP는 데이터베이스 연결을 효율적으로 관리하고 성능을 최적화하기 위한 기술이다. JDBC 위에서 DBCP가 동작되는 형태이다.
특히 대규모 애플리케이션이나 높은 트래픽의 서비스에서는 DBCP 방식을 사용해 성능을 최적화하는 것이 중요한데, 왜 DBCP를 사용하는 것이며 어떤 설정값이 있는지 알아보려고 한다.
1. JDBC(Java DataBase Connectivity)
자바에서 데이터베이스에 접근하고 쿼리를 실행하기 위한 표준 API이다.
개발자가 JDBC API를 이용해 데이터베이스 관련 작업을 작성하면, JDBC API는 SQL문을 실행하고 결과를 조회할 수 있도록 한다. 따라서 데이터베이스 내부 동작 방식에 대해 신경쓰지 않아도 된다.
JDBC 드라이버는 여러 종류가 있으며, 각 DBMS에 맞게 설계되어 있다. 만약 데이터베이스로 MySQL을 사용하다가 Oracle로 변경한다면 JDBC 드라이버를 교체해주면 된다. (물론 쿼리 작성한 곳에서 약간의 문법 수정도 필요하다)
동작 흐름
Java 프로그램 → JDBC API → JDBC Driver → DB
JDBC API를 사용하기 위해서는 *JDBC Driver를 먼저 로딩한 후 데이터베이스와 연결한다.
- JDBC 드라이버 로드
- DB 연결 (커넥션 객체 생성) -
DriverManager.getConnection() - SQL 쿼리 실행 - 쿼리 수행을 위한
PreparedStatement객체 생성,executeQuery()로 쿼리 실행 - 결과 처리 -
ResultSet객체에 결과를 받아옴 - 사용했던
ResultSet,PreparedStatement,Connection을 close
* JDBC Driver ?
데이터베이스와의 통신을 담당하는 인터페이스로, 각 DBMS에 맞는 JDBC 드라이버가 존재한다.
JDBC 드라이버는 자바 프로그램의 요청을 DBMS가 이해할 수 있는 형태로 변환해주고 처리한다.
JDBC 방식의 단점
일반적인 JDBC는 DB에 요청을 보낼 때마다 매번 DB 연결을 열고 닫는다. 이렇게 매 요청마다 DB 연결을 열고 닫는 방식을 JDBC 방식이라고 한다. JDBC 방식은 사람들이 많이 접속하는 서비스에서 계속 드라이버를 로드하고, 객체를 생성하기 때문에 비효율적으로 동작하기때문에 상용 서비스에서 사용하는 경우는 드물다. (보통 DB 연결 시 TCP 통신을 이용)
즉, 데이터베이스 연결이 반복적으로 열리고 닫히면서 성능 저하가 발생해 비효율적이다.
그래서 등장한 것이 DBCP이다. DBCP는 WAS 실행 시 미리 일정량의 DB 커넥션 객체를 생성하고 Pool이라는 공간에 저장해 재사용한다. DB 연결 요청이 있으면, Pool에서 커넥션 객체를 가져다 쓰고 반환한다.
먼저 DBCP 방식에서 사용되는 개념인 Connection과 Connection Pool에 대해 알아보자
2. Connection & Connection Pool
Connection
- DB를 사용하기 위해 DB와 애플리케이션 간 통신을 할 수 있는 수단
- 네트워크 상의 연결 자체를 의미
Connection Pool
- 커넥션 객체를 저장하는 저장소
- 웹 컨테이너(WAS)가 실행되면서 일정량의 커넥션 객체를 미리 만들고 저장소에 보관해둔다. 클라이언트의 요청이 오면 미리 생성된 커넥션 객체를 빌려주고 해당 객체의 임무가 완료되면 다시 저장소에 반납한다.
3. DBCP (DataBase Connection Pool)
데이터베이스 커넥션을 재사용할 수 있도록 풀(Pool)로 관리하는 기술을 말한다.
웹 컨테이너가 실행되면 일정 개수만큼 DB 커넥션 객체를 생성해 Pool에 넣고, 필요할 때마다 가져다 쓰고 반납하는 방식이다. 이미 생성된 연결을 재사용하기 때문에 자원을 효율적으로 사용할 수 있고, 미리 만든 연결은 메모리 상에 등록해 놓기 때문에 사용자 요청 시 빠른 응답이 가능하다.
DBCP 종류로는 Apache Commons DBCP2, HikariCP, Tomcat JDBC Connection Pool 등이 있다. (Spring Boot 2.0 부터는 기본 커넥션 풀 라이브러리로 HikariCP를 제공한다)
동작 흐름
- 웹 컨테이너(WAS)가 실행되면서 일정 개수의 Connection 객체를 미리 Pool에 생성
- DB 요청이 오면 Pool에 이미 생성된 Connection 객체를 가져다 쓰고, 다쓰면 Pool에 반환한다.
DBCP 방식은 자동으로 연결을 관리하므로 개발자의 부담이 줄어들고 코드의 복잡성을 줄여줄 수 있다. 실무에서는 커넥션 풀을 이용해 얻는 이점이 크기 때문에 기본으로 사용하는 것이 좋다.
+ JNDI (Java Naming and Directory Interface) ?
JDBC와 DBCP에 대해 자료를 찾아보니 JNDI라는 개념이 자주 등장한다.
JNDI는 디렉터리 서비스에서 제공하는 데이터와 객체를 발견하고 참고하기 위한 자바 API이다.
JNDI를 사용하면 DBCP 관련 설정을 서버의 디렉터리에 설정해 WAS 단에서 커넥션 관리를 할 수 있다. 이 경우 WAS에서 서버를 여러개 운영하는 경우, DBCP 설정을 한곳에서 설정할 수 있으며 설정값에 변경이 있을 경우 수정이 용이하다는 이점이 있다.
4. DBCP 옵션
각 DBCP마다 옵션을 설정하는 변수가 다르기 때문에 각 공식문서를 확인해야 한다.
여기서는 Spring에서 기본으로 사용하는 HkariCP에서 자주 사용되는 옵션들을 다음 링크를 참고해 일부 정리했다.
GitHub - brettwooldridge/HikariCP: 光 HikariCP・A solid, high-performance, JDBC connection pool at last.
光 HikariCP・A solid, high-performance, JDBC connection pool at last. - brettwooldridge/HikariCP
github.com
다음 옵션들은 Spring application.properties 및 application.yml로 설정할 수 있다.
- maximumPoolSize : Pool에서 유지할 수 있는 최대 커넥션 수 (default : 10)
- minimumIdle : Pool에서 유지할 최소 유휴 커넥션 수. maximumPoolSize와 동일하게 설정할 것을 권장 (default : 10)
- connectionTimeout : 커넥션을 얻기 위해 기다릴 수 있는 최대 시간. 이 때까지 커넥션을 얻지 못하면 예외가 발생한다. (default : 30,000 (30초))
- idleTimeout : Pool에서 유휴 상태 커넥션들의 유지될 수 있는 최대 시간. minimumIdle이 maximumPoolSize보다 작게 설정된 경우에만 이 값을 설정할 수 있다. (default : 600,000 (10분))
- maxLifetime : 커넥션의 최대 수명. 사용 중인 커넥션이 최대수명을 초과했어도, 종료된 후에 제거된다. (default : 180,000 (30분))
커넥션 풀을 크게 설정하면 클라이언트의 요청 대기 시간이 줄어든다. 하지만 그만큼 커넥션 객체가 많이 생성되기 때문에 메모리를 소모하게 된다. 반대로 커넥션 풀을 작게 설정하면 클라이언트의 요청 대기 시간이 길어진다. 따라서 요청량 따라 적당한 수의 커넥션 객체를 생성해줘야 한다.
Hikari CP 권장 옵션
Hikari CP의 공식 문서에는 다음과 같이 옵션을 설정할 것을 권장한다.
1. minimumIdle == maximumPoolSize
- minimumIdle(5개) < maximumPoolSize(10개)인 경우, 항상 5개의 커넥션을 동시에 사용하는 상황에서 1개의 커넥션이 추가로 요청된다면 커넥션이 생성되고, minimumIdle이 5이므로 1개의 커넥션에 대해서는 폐기하는 작업이 필요하다.
- mininumIdle > maximumPoolSize인 경우에도 마찬가지로 매번 커넥션을 생성하고 폐기하는 작업이 필요하다.
-> 따라서 커넥션을 매번 생성했다 닫는 비용이 발생할 수 있기 때문에 두 값을 동일하게 설정할 것을 권장한다.
2. PostgreSQL에서 제공한 공식. Hikari CP 공식문서에서 다른 전반적인 데이터베이스에 적용될 수 있는 공식이라고 제시하고 있다.
connections = ((core_count) * 2) + effective_spindle_count)- connections : 최대 커넥션 수
- core_count : 서버의 CPU 코어 수
- 최대 커넥션 수가 코어 수에 근접할수록 좋지만 CPU와 디스크/네트워크의 속도 차이로 인해 계수 2를 곱해준다.
- 속도 차이로 인해 스레드가 디스크와 같은 작업에서 블로킹되는 시간에 다른 스레드의 작업을 처리할 수 있는 여유가 생기기 때문
- effective_spindle_count : DB 서버가 관리할 수 있는 동시 I/O 요청 수
- 디스크 스핀들(spindle) 수
- 디스크가 16개 있는 경우, DB 서버는 동시에 16개의 I/O 요청을 처리할 수 있다.
3. Dead Lock을 피하기 위한 Connection Pool 공식.
pool size = Tn x (Cm - 1) + 1- Dead Lock을 피하기 위한 Connection Pool 공식.
- Tn : WAS의 전체 스레드 개수
- Cm : 하나의 스레드가 작업을 수행하기 위해 동시에 필요한 DB Connection 수
- 위 공식은 데드락이 발생하지 않을 최소값이다. 따라서 +1보다 조금 더 여유로운 최적의 값을 찾아내는 것이 좋다.
⇒ 위 세가지 공식을 참고하되, 테스트를 통해 각 시스템에 적절한 값을 찾는게 좋은 방법이다.
+ 3번 Dead Lock을 피하기 위한 Connection Pool 공식에 대하여
참고 우아한 형제들 기술블로그 - HikariCP Dead lock에서 벗어나기
데드락 발생 조건
- Thread-1이 필요한 커넥션 수 : 2개
- 현재 Pool Size : 1개
만약 Thread-1이 작업을 수행하기 위해 2개의 DB 커넥션이 필요하고, 현재 pool size는 1이라고 하자. 그럼 Thread-1이 작업을 수행하기 위해 Pool에서 커넥션 1개를 받아오는데, Thread-1은 아직 하나의 커넥션이 더 필요하므로 다른 스레드로부터 1개의 커넥션이 반납될 때까지 대기한다. Thread-1은 자기자신이 커넥션을 반납하는 것을 대기하는 상황이고, 데드락이 발생한다.
이제 공식을 사용해 해결해보자
pool size = Tn x (Cm - 1) + 1- 스레드 최대 개수 : 5개
- 하나의 스레드 당 필요한 커넥션 수 : 2개
- Pool Size = 5 x (2 - 1) + 1
스레드 최대 개수가 5이고, 동시에 필요한 커넥션 수가 2개라고 하자. 위 공식을 적용해보면, pool size는 6개이다. Thread-1~5까지 5개의 스레드가 동시에 커넥션을 요청해 하나씩 나눠가졌고, Thread-1이 남은 한개의 커넥션을 더 획득했다. Thread-1을 제외한 나머지 스레드들은 커넥션 객체를 얻기 위해 대기하고 있고, Thread-1은 로직을 처리한뒤 Pool에 커넥션을 반납한다. 그럼 Pool에 반납된 커넥션은 2개가 되고, 나머지 스레드 중 2개의 스레드가 커넥션을 획득해 로직을 처리할 수 있다. 나머지 스레드들에 대해서도 마찬가지이다.
공식에서 +1개의 커넥션이 데드락을 해결하는 핵심 key가 되는 것이다.
5. Spring 실습
application.properties
# == HikariCP SETTING ==
spring.datasource.hikari.maximum-pool-size=2
spring.datasource.hikari.connection-timeout=3000maximumPoolSize와 connectionTimeout값을 설정해준다.
Controller
@GetMapping("/test")
public void hikariTest() {
System.out.println("=== start!!! ===");
service.hikariTest()
System.out.println("=== finish!!! ===");
}컨트롤러로 요청이 들어오면 “=== start!!! ===”을 출력하고 서비스단 메서드를 요청한다.
Service
@Transactional(readOnly = true)
public void hikariTest() {
try {
System.out.println("=== sleep!!! ===");
Thread.sleep(10000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}서비스로 요청이 들어오면 "=== sleep!!! ==="을 출력하고 Thread.sleep으로 10초간 스레드를 정지시킨다.
(커넥션을 얻기 위해 @Transactional 어노테이션을 추가)
각 요청은 브라우저와 포스트맨으로 실행했다.
현재 Pool 사이즈는 2 이므로 두 요청이 모두 정상적으로 컨트롤러단의 “=== finish!!! ===”가 출력된다.
+ maximumPoolSize를 1로 바꾸면 어떻게 될까?
# == HikariCP SETTING ==
spring.datasource.hikari.maximum-pool-size=1
spring.datasource.hikari.connection-timeout=3000두 요청을 실행했을 때, Pool 사이즈는 1이므로 먼저 들어온 스레드가 커넥션을 얻고 10초간 정지한다. 그럼 다른 스레드는 커넥션을 얻지 못한채 대기하다가 connectionTimeout인 3초를 초과하기 때문에 예외가 발생할 것이다.
먼저 들어온 스레드가 10초간 대기상태에 들어가면, 다른 스레드는 대기하다가 connectionTimeout인 3초를 초과해 request timed out 예외가 발생한다.
6. 마무리
학생 때 만들었던 첫 웹 프로젝트에서 JDBC API를 직접 호출하는 DriverManager.getConnection(DBURL, DBName, DBPW), executeQuery() 같은 코드를 짰는데, 당시 try-catch문도 많이 사용하고 중복코드가 많았던 기억이 있다. 그때는 DBCP라는 것이 있는지도 몰랐고ㅎ 적은 트래픽 요청의 서비스라 이런 커넥션 관리 기술을 신경쓰지 못하고 오로지 로직 구현만 했던 것 같다.
이후 개발에서 Spring 프레임워크 + JPA를 사용하다보니 직접적으로 JDBC API를 사용하는 경우가 없었고, HikariCP 관련 설정도 기본값을 사용했었다. 이번 기회에 이런 기술들이 왜 생겨났고, 왜 필요한지에 대해 생각할 수 있었다. DB 관련 설정은 어떤 서비스에서나 중요한 요소이므로 추후 프로젝트를 설계할 때는 이런 설정값들을 신경써서 구현해야겠다.
참고자료 😃
https://adjh54.tistory.com/430
https://egg-stone.tistory.com/16
https://steady-coding.tistory.com/564#google_vignette
https://techblog.woowahan.com/2664/
https://techblog.woowahan.com/2663/
'DB' 카테고리의 다른 글
| [DB] Redis 개념과 데이터 타입 실습 (8) | 2024.11.04 |
|---|---|
| [DB] B-Tree, B+Tree - DB Index (0) | 2024.04.18 |
| [DB] NoSQL (NotOnly SQL) (1) | 2024.03.28 |
| [DB] 데이터베이스 정규화 (Normalization) (1) | 2024.03.26 |
| [DB] 트랜잭션 격리수준 (Transaction Isolation) (0) | 2024.03.15 |