
SpringBoot에서 Redis를 사용해보자 ❕
1. Redis 적용 목적
Redis는 데이터를 메모리에 저장하기 때문에 빠른 조회가 가능하며, 반복적으로 요청되는 데이터를 캐싱해 매번 데이터베이스와 통신하는 비용을 아낄 수 있다.

이번 학습에서는 Spring에 Redis를 적용하는 방법을 정리한 뒤, 다량의 데이터를 지속적으로 조회하여 Redis 적용 전/후의 성능 차이를 비교해보려고 한다.
2. 설정
spring boot 버전 : `3.3.5`
2-1. 의존성 추가 및 환경변수 설정
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-data-redis'- 해당 의존성을 통해, Spring Boot에서 여러 Redis 드라이버(Jedis, Lettuce)를 추상화하여 사용할 수 있도록 한다.
application.yaml
# redis 설정
spring:
data:
redis:
host: 127.0.0.1
port: 6379
# 기본 만료 시간
app:
redis:
expire:
default: 60
| 속성 | 설명 |
| spring.redis.host | Redis 서버의 호스트 이름 |
| spring.redis.port | Redis 서버의 포트 번호 |
| spring.redis.password | Redis 서버에 접근하기 위한 비밀번호 |
| spring.redis.ssl | SSL 연결 사용 여부 |
| spring.redis.timeout | Redis 서버와의 연결 시간 제한 |
| spring.redis.database | 사용할 Redis 데이터베이스의 인덱스 (0~15번까지 총 16개를 가질 수 있다) |
| spring.redis.lettuce.pool.max-active | 동시에 유지할 수 있는 최대 연결 수 |
| spring.redis.lettuce.pool.max-idle | 유휴 상태에서 유지할 수 있는 최대 연결 수 |
| spring.redis.lettuce.pool.min-idle | 유휴 상태에서 유지할 수 있는 최소 연결 수 |
2-2. Redis 커넥션 정보 설정
주요 클래스
- `RedisConnectionFactory`
- Spring Data Redis에서 제공하는 인터페이스로, RedisConnection을 생성하고 관리한다.
- 구현체로 LettuceConnectionFactory, JedisConnectionFactory가 주로 사용되는데 Spring Boot 2.0 버전 부터는 비동기 방식인 LettuceConnectionFactory가 기본으로 사용된다.
- `RedisTemplate<String, Object>`
- Redis와 상호작용할 수 있는 다양한 메서드를 제공한다.
- Thread-safe하며, 재사용이 가능하다.
- ex)
opsForValue(),delete()등
- `RedisCacheManager`
- Spring Cache를 사용하는 것처럼, Spring에서 Redis를 캐시로 사용하는 Cache 객체를 생성하고 관리한다.
- 애플리케이션이 캐시를 요청하면 RedisCacheManager가 요청을 처리하고, Redis에 데이터를 저장하거나 가져온다.
- Spring Cache 활성화를 위해 프로젝트 루트 클래스에
@EnableCaching을 추가하면 된다.
RedisConfig.java
@Configuration
@RequiredArgsConstructor
public class RedisConfig {
private final RedisProperties redisProperties;
private final RedisConnectionFactory redisConnectionFactory;
@Value("${app.redis.expire.default}")
private long defaultExpireSecond;
@Bean
public ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS); // timestamp를 설정하지 못하도록
mapper.registerModules(new JavaTimeModule(), new Jdk8Module()); // java의 날짜를 인식할 수 있도록
return mapper;
}
// 외부 redis 서버와의 통신을 위해 직렬화/역직렬화 진행
@Bean
public RedisCacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory, ObjectMapper objectMapper) {
RedisCacheConfiguration configuration = RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues() // null 허용 X
.entryTtl(Duration.ofSeconds(defaultExpireSecond)) // default 만료 시간 설정
.serializeKeysWith(RedisSerializationContext // key값 직렬화
.SerializationPair
.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext // value값 직렬화
.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer(objectMapper)));
return RedisCacheManager.builder(redisConnectionFactory)
.cacheDefaults(configuration)
.build();
}
}Redis와의 연결을 설정하기 위해 환경 변수에서 설정한 host, port 정보를 기반으로 Redis 클라이언트를 구성해야한다. spring boot 2.0 이상부터는 RedisProperties를 통해 host, port를 가져올 수 있으며 RedisConnectionFactory, RedisTemplate, StringTemplate들이 빈으로 자동 생성된다.
외부 Redis서버와 데이터를 주고받아야 하므로 직렬화/역직렬화를 통해 데이터를 주고받을 수 있도록 RedisCacheManager를 설정했다.
Serializer 구현체 종류
JdkSerializationRedisSerializer- jdk에서 기본으로 제공하는 직렬화 방식으로, default로 해당 구현체를 사용하게 된다.
- Redis에 저장하고자하는 객체는 모두 java.io.Serializable 인터페이스를 구현하고 있어야 한다.
- 객체의 메타 정보(패키지 정보, 타입 정보)를 같이 직렬화하여 저장한다.
GenericJackson2JsonRedisSerializer- 별도의 class type을 설정해주지 않아도 자동으로 객체를 JSON 형식으로 직렬화한다.
- 객체의 메타 정보를 같이 직렬화하여 저장한다.
- MSA와 같이 여러 애플리케이션이 상호작용하며 같은 데이터를 사용하는 경우, 모두 같은 패키지 구조를 가져야 한다는 문제가 있다.
Jackson2JsonRedisSerializer- 객체를 JSON 형식으로 직렬화하며, class type을 매번 지정해줘야 한다.
- 사용하는 class type 종류가 많아진다면 구현이 복잡해진다는 단점이 있다.
StringRedisSerializer- 문자열 데이터를 그대로 직렬화하며, class type을 설정해주지 않아도 된다.
- Redis에서 key는 보통 String 타입이므로, key직렬화에 자주 사용된다.
2-3. 캐싱 사용
루트 클래스
@EnableCaching
@SpringBootApplication
public class RedisApplication {
public static void main(String[] args) {
SpringApplication.run(RedisApplication.class, args);
}
}- @EnableCaching
- Spring에게 Redis를 사용한다는 것을 알려주는 어노테이션
- @Cacheable, @CachePut, @CacheEvict 캐싱 어노테이션의 사용을 인식할 수 있게 된다.
- @Cacheable : 캐시에 데이터가 존재하면 해당 데이터를 반환하고, 없으면 메서드를 실행하여 결과를 캐시에 저장한다.
- @CachePut : 항상 메서드를 실행하고 결과를 캐시에 저장
- @CacheEvict : 지정한 키의 캐시 데이터를 삭제
+ 주의
테스트를 진행하면서 Redis 환경변수를 잘못 설정했는데, 애플리케이션이 정상적으로 실행되는 것을 확인했다. 확인해보니 Redis는 lazy하게 db 커넥션을 연결하기 때문에 포트번호나 설정값을 잘못 설정해도 애플리케이션이 실행되는 것이었다. ^따라서 연결을 보장하는 작업이 필요한 서비스에서는 기본 쿼리 동작을 실행시킴으로써 레디스 연결을 확인해야 한다.^
3. 실습
3-1. 컨트롤러 & 서비스
@RequestMapping("/schedules")
@RestController
@RequiredArgsConstructor
public class SearchController {
private final SearchService searchService;
@GetMapping("/date")
public ResponseEntity<?> searchListByDate(SearchReq dto) {
return new ResponseEntity<>(searchService.searchListByDate(dto.getStartDate(), dto.getEndDate()), HttpStatusCode.valueOf(200));
}
}
@Cacheable(value = "schedules.search", key = "#startDate.toString() + #endDate.toString()")
@Transactional(readOnly = true)
public List<Schedule> searchListByDate(LocalDateTime startDate, LocalDateTime endDate) {
return searchRepository.findAllByDate(startDate, endDate);
}캐싱하려는 데이터를 반환하는 메서드에 @Cacheable을 추가한다. 첫 요청에서 해당 결과를 캐싱하고, 메서드가 재호출됐을 때 캐시에 해당 key를 조회하여 데이터가 존재한다면 데이터를 바로 반환하고, 그렇지 않다면 메서드를 실행하여 캐싱한다.
@Cacheable

- key
- Spring Cache는 기본적으로 메서드의 파라미터를 캐시 key로 사용한다.
- 특정 인자를 key로 지정하려고 한다면
#인자값형태로 설정할 수 있다. - 클래스의 정적 메서드나 상수를 사용한다면
T(클래스명)을 통해 접근할 수 있다.
- value
- 캐시 이름을 설정하는 옵션으로, 캐시 key의 prefix 역할을 한다.
- 만약 특정 이름으로 저장된 데이터를 모두 삭제하고 싶다면 이 값을 사용하면 된다.
- cacheManager
- 어떤 캐시 매니저를 사용할 지 설정할 수 있다.
- 별도로 지정하지 않으면 default로 설정된 캐시 매니저를 사용한다.
3-2. 결과 확인

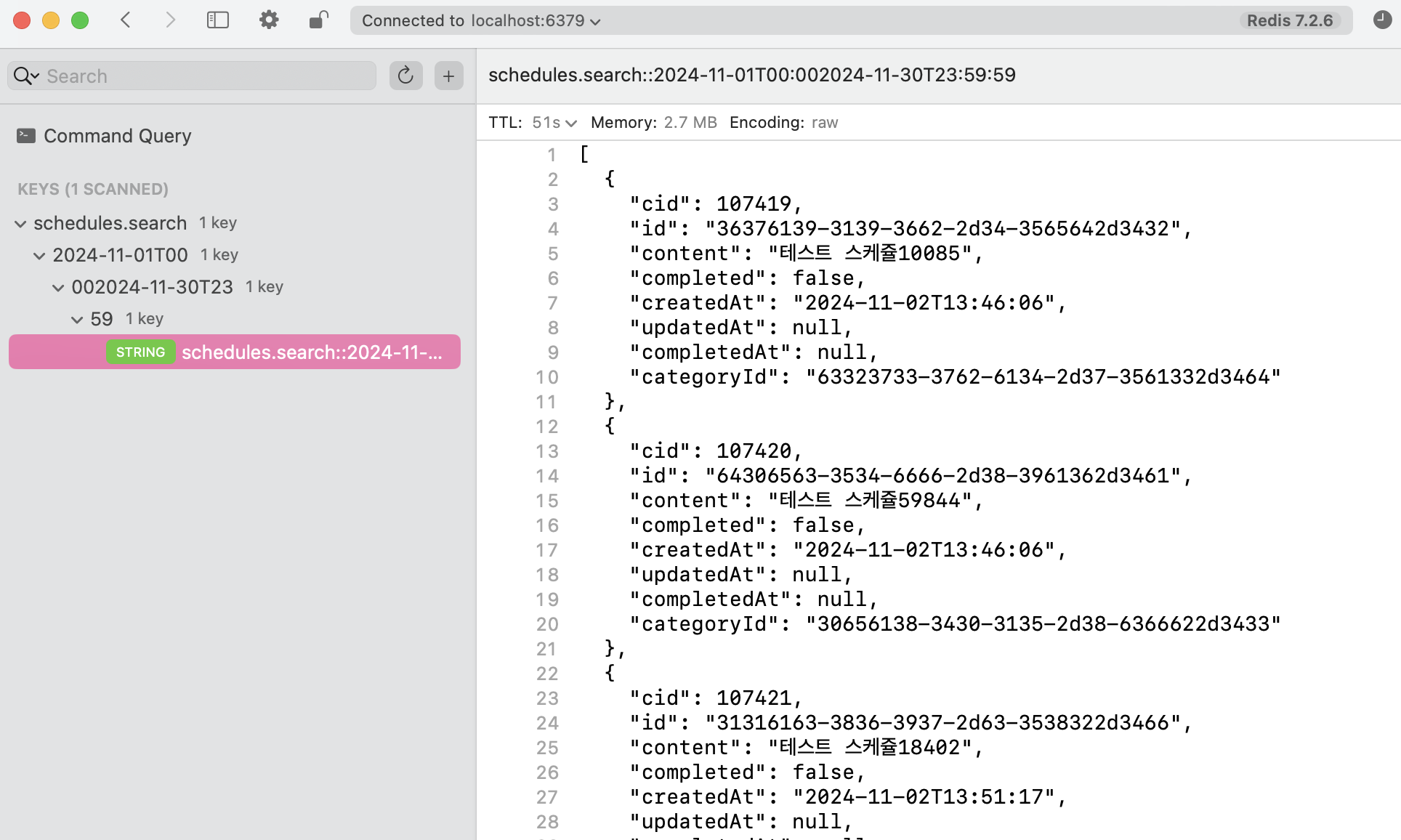
Redis를 통해 데이터를 확인해보면 조회 결과가 정상적으로 저장되었고, 설정했던 만료시간이 지나면 자동으로 제거된다.
하지만 key 값에 :이 포함되어 있어, 이를 기준으로 key가 나누어질 수 있다. 만약 이 부분을 Unix 타임스탬프로 변환한다면 다음과 같이 작성할 수도 있다.
@Cacheable(value = "schedules.search", key = "#startDate.toEpochSecond(T(java.time.ZoneOffset).UTC) + '-' + #endDate.toEpochSecond(T(java.time.ZoneOffset).UTC)")
4. 성능 테스트
성능 테스트는 *Locust를 통해 진행했다.
* Locust ?
Python 언어로 개발되어 스크립트 작성으로 테스트를 진행할 수 있는 도구이다. 분산된 테스트를 지원하며, 동적인 부하를 생성할 수 있다. 또한, 웹 기반 대시 보드도 제공하여 실시간 결과를 모니터링할 수 있다.
4-1. Locust 세팅
pip install locust # locsut 설치from datetime import datetime, timedelta
from locust import HttpUser, task, between
"""
스케쥴 데이터를 지속적으로 요청하는 테스트
"""
class RedisTest(HttpUser):
wait_time = between(1, 2) # 스레드 시작 여유 시간 설정
today = datetime.now()
# 이번 달의 첫 일, 마지막 일 세팅
startDate = datetime.strftime(datetime(today.year, today.month, 1),"%Y.%m.%d 00:00:00")
endDate = datetime.strftime(datetime(today.year, today.month+1, 1) - timedelta(days=1), "%Y.%m.%d 23:59:59")
@task
def search(self):
# 한달 간 등록된 데이터 조회
self.client.get("/schedules/date", params={
"startDate": self.startDate,
"endDate": self.endDate
})
locust -f RedisTest.py로 실행하여, localhost:8090으로 접속한다.
지금 테스트에서는 조회 기간 동안의 데이터는 미리 총 1만개를 생성해두었고, 현재 테스트에서는 10명씩 늘어나 총 100명의 유저가 데이터를 조회하도록 세팅했다.
4-2. 결과 비교
1) 캐싱 적용 전


2) 캐싱 적용 후


캐싱 적용 전/후를 비교해보면 캐싱을 적용한 후 1초당 처리하는 요청량(RPS)은 증가했으며, 응답 시간도 크게 감소된 것을 확인할 수 있다. 또한, CPU 사용량은 크게 감소한 반면 메모리 사용량은 다소 증가했음을 알 수 있다. 캐싱 적용으로 사용자 경험과 서버 성능 개선에 중요한 역할을 할 수 있을 것이다. 다만 데이터 양과 사용자 수가 증가할 경우, 운영 환경에서 메모리 부하를 피하기 위한 캐싱 전략이 필요할 것으로 보인다.
5. 마무리
최근 프로젝트를 리팩토링하면서 Redis를 적용해봤는데, 복습할 겸 블로그에 정리하는 시간을 가졌다. 복습 과정에서 Redis가 데이터베이스 연결을 lazy 방식으로 처리한다는 점을 새롭게 알게 되었고, 날짜 타입을 key나 value로 저장할 때 :가 포함되어 의도치 않은 형태로 저장되는 문제도 발견했다. 실제 운영 환경에서는 캐싱을 적용하는 것을 넘어, 이러한 문제에 대해 어떻게 대처할 지 미리 정의하고 관리하는 것이 중요하다고 느꼈다. 조만간 캐시 데이터를 어떤 방식으로 갱신하고 만료시킬지에 대한 기준도 고민해보고 프로젝트에 반영해보려고 한다.
참고자료 😃
https://bcp0109.tistory.com/328
https://jistol.github.io/spring/2017/02/09/springboot-cache-key/
https://github.com/binghe819/TIL/blob/master/Spring/Redis/redis serializer/serializer.md
'Spring' 카테고리의 다른 글
| [Spring] Apache Poi 엑셀 다운로드 개선 및 성능 확인 (+ SXSSF) (1) | 2024.12.06 |
|---|---|
| [Spring] Log4J, Logback, Log4J2 개념 (+Logback실습) (1) | 2024.11.21 |
| [Spring] Spring에서 동시성 이슈를 해결하는 방법 (1) | 2024.10.02 |
| [Spring] Apache POI (+ Multipart, Spring 구현) (0) | 2024.05.14 |
| [Spring] V2. OAuth2.0으로 소셜로그인 구현하기 (spring-security-oauth2-client 사용) (0) | 2024.03.23 |